2,139,149 events recorded by gharchive.org of which 2,139,149 were push events containing 3,273,899 commit messages that amount to 275,790,032 characters filtered with words.py@e23d022007... to these 31 messages:
Creates a new tile for the predator ship (#1400)
-
erm
-
yer
-
fuck you shaddeh
this music, i swear to fucking god, was playing outside my window at midnight last night and this is the best recording i managed to get of it
pinctrl: qcom: Avoid glitching lines when we first mux to output
Back in the description of commit e440e30e26dd ("arm64: dts: qcom: sc7180: Avoid glitching SPI CS at bootup on trogdor") we described a problem that we were seeing on trogdor devices. I'll re-summarize here but you can also re-read the original commit.
On trogdor devices, the BIOS is setting up the SPI chip select as:
- mux special function (SPI chip select)
- output enable
- output low (unused because we've muxed as special function)
In the kernel, however, we've moved away from using the chip select line as special function. Since the kernel wants to fully control the chip select it's far more efficient to treat the line as a GPIO rather than sending packet-like commands to the GENI firmware every time we want the line to toggle.
When we transition from how the BIOS had the pin configured to how the kernel has the pin configured we end up glitching the line. That's because we first change the mux of the line and then later set its output. This glitch is bad and can confuse the device on the other end of the line.
The old commit e440e30e26dd ("arm64: dts: qcom: sc7180: Avoid glitching SPI CS at bootup on trogdor") fixed the glitch, though the solution was far from elegant. It essentially did the thing that everyone always hates: encoding a sequential program in device tree, even if it's a simple one. It also, unfortunately, got broken by commit b991f8c3622c ("pinctrl: core: Handling pinmux and pinconf separately"). After that commit we did all the muxing first even though the config (set the pin to output high) was listed first. :(
I looked at ideas for how to solve this more properly. My first thought was to use the "init" pinctrl state. In theory the "init" pinctrl state is supposed to be exactly for achieving glitch-free transitions. My dream would have been for the "init" pinctrl to do nothing at all. That would let us delay the automatic pin muxing until the driver could set things up and call pinctrl_init_done(). In other words, my dream was:
/* Request the GPIO; init it 1 (because DT says GPIO_ACTIVE_LOW) / devm_gpiod_get_index(dev, "cs", GPIOD_OUT_LOW); / Output should be right, so we can remux, yay! */ pinctrl_init_done(dev);
Unfortunately, it didn't work out. The primary reason is that the MSM GPIO driver implements gpio_request_enable(). As documented in pinmux.h, that function automatically remuxes a line as a GPIO. ...and it does this remuxing before specifying the output of the pin. You can see in gpiod_get_index() that we call gpiod_request() before gpiod_configure_flags(). gpiod_request() isn't passed any flags so it has no idea what the eventual output will be.
We could have debates about whether or not the automatic remuxing to GPIO for the MSM pinctrl was a good idea or not, but at this point I think there is a plethora of code that's relying on it and I certainly wouldn't suggest changing it.
Alternatively, we could try to come up with a way to pass the initial output state to gpio_request_enable() and plumb all that through. That seems like it would be doable, but we'd have to plumb it through several layers in the stack.
This patch implements yet another alternative. Here, we specifically avoid glitching the first time a pin is muxed to GPIO function if the direction of the pin is output. The idea is that we can read the state of the pin before we set the mux and make sure that the re-mux won't change the state.
NOTES:
- We only do this the first time since later swaps between mux states might want to preserve the old output value. In other words, I wouldn't want to break a driver that did: gpiod_set_value(g, 1); pinctrl_select_state(pinctrl, special_state); pinctrl_select_default_state(); /* We should be driving 1 even if "special_state" made the pin 0 */
- It's safe to do this the first time since the driver couldn't have explicitly set a state. In order to even be able to control the GPIO (at least using gpiod) we have to have requested it which would have counted as the first mux.
- In theory, instead of keeping track of the first time a pin was set as a GPIO we could enable the glitch-free behavior only when msm_pinmux_request_gpio() is in the callchain. That works an enables my "dream" implementation above where we use an "init" state to solve this. However, it's nice not to have to do this. By handling just the first transition to GPIO we can simply let the normal "default" remuxing happen and we can be assured that there won't be a glitch.
Before this change I could see the glitch reported on the EC console when booting. It would say this when booting the kernel: Unexpected state 1 in CSNRE ISR
After this change there is no error reported.
Note that I haven't reproduced the original problem described in e440e30e26dd ("arm64: dts: qcom: sc7180: Avoid glitching SPI CS at bootup on trogdor") but I could believe it might happen in certain timing conditions.
Fixes: b991f8c3622c ("pinctrl: core: Handling pinmux and pinconf separately") Signed-off-by: Douglas Anderson dianders@chromium.org Reviewed-by: Stephen Boyd swboyd@chromium.org Link: https://lore.kernel.org/r/20221014103217.1.I656bb2c976ed626e5d37294eb252c1cf3be769dc@changeid Signed-off-by: Linus Walleij linus.walleij@linaro.org
Add files via upload
Final project: Python for Data Analytics: Spring 2022
I found my data set at https://data.norfolk.gov/Education/Library-Circulation-Statistics/e68x-a47n per the website “This dataset contains information about circulation (checkouts) by item type for each Norfolk Public Library branch location by month.” I decided to examine the various DVD collections to include movies that patrons can download as well. My goal was to take a slice of all the data for those collections and match them across each location where patrons were checking out items. Thus, I had to do some investigation into the structure of the Norfolk Public Library system (https://www.norfolkpubliclibrary.org/about-npl/hours-locations ) in order to decide how I was going to approach cleaning my data (combining data points and eliminating data points) before I could start to use the data.
While I was sorting and sifting through the data; I used the internet a lot for exploring more Python code. The websites that I visited most frequently were as follows:
• https://www.python-graph-gallery.com/stacked-area-plot/
• https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.replace.html
• https://realpython.com/python-counter/
• https://datacarpentry.org/python-ecology-lesson/03-index-slice-subset/
• https://pythonexamples.org/pandas-dataframe-sort-by-column/
• https://towardsdatascience.com/data-grouping-in-python-d64f1203f8d3
• https://pythonguides.com/category/python-tutorials/matplotlib/
During my exploration of Matplotlib and my dataframes, I tried several different types of graphs (mostly based on my ability to write the code) such as Scatter plots, Line charts, Histogram charts, Bar charts, and Violin plots which were the most fun to plot. Sadly, most of my plotting and there for my graphs were underwhelming. Ultimately, I spent most of my time resifting, resorting, and slicing the data into more manageable pieces so that I could attempt to illicit a finding. I do believe that I more than likely left a lot of good data on the “cutting room floor” but I tried. Not surprising to me was the finding that circulation of DVDs and even the use of downloaded movies took a nose dive across all the Norfolk Public Library. (I am a librarian by trade and worked in a public library during the same timeframes covered by the “Year” data points within the dataset. I know firsthand how library item use were impacted here in the Capital District and I was curious to see if a southern state would show less deviation.)
Overall, I know that I could and should have done better with the final project. However, I have learned a great deal and I really enjoyed the class. Okay, I think that pretty much covers it. My final project has multiple graphs and a few different types, shows (mean, mode, median) for select data, shows that I sort of know how to use (font attributes –size, color, rotation and figure attributes –size), and shows that I can slice and dice a dataframe decently (maybe just in my opinion, LOL)
gives medical ert a health analyzer (#70244)
-
gives medical ert a health analyzer
-
fuck you upgrades your analyzer
Updated night order for all roles
Updated night order for all roles to match the order at https://script.bloodontheclocktower.com/data/nightsheet.json
Some noticeable changes:
- Legion was moved much earlier in the order of demons (relevant if a another demon is made in a legion game, you can keep it around and kill it with legion before it kills on a subsequent night)
- Amnesiac was moved much later in night order (a more reasonable place for the most common type of amni abilities)
- Magician was given a night order for N1
- Pixie was given a night order for other nights
Unfucking the shit
Manually downloaded each branch then click and dragged them into the project to overwrite the eldritch bullshit
sched/core: Implement new approach to scale select_idle_cpu()
Hackbench recently suffered a bunch of pain, first by commit:
4c77b18cf8b7 ("sched/fair: Make select_idle_cpu() more aggressive")
and then by commit:
c743f0a5c50f ("sched/fair, cpumask: Export for_each_cpu_wrap()")
which fixed a bug in the initial for_each_cpu_wrap() implementation that made select_idle_cpu() even more expensive. The bug was that it would skip over CPUs when bits were consequtive in the bitmask.
This however gave me an idea to fix select_idle_cpu(); where the old scheme was a cliff-edge throttle on idle scanning, this introduces a more gradual approach. Instead of stopping to scan entirely, we limit how many CPUs we scan.
Initial benchmarks show that it mostly recovers hackbench while not hurting anything else, except Mason's schbench, but not as bad as the old thing.
It also appears to recover the tbench high-end, which also suffered like hackbench.
Tested-by: Matt Fleming matt@codeblueprint.co.uk Signed-off-by: Peter Zijlstra (Intel) peterz@infradead.org Cc: Chris Mason clm@fb.com Cc: Linus Torvalds torvalds@linux-foundation.org Cc: Mike Galbraith efault@gmx.de Cc: Peter Zijlstra peterz@infradead.org Cc: Thomas Gleixner tglx@linutronix.de Cc: hpa@zytor.com Cc: kitsunyan kitsunyan@inbox.ru Cc: linux-kernel@vger.kernel.org Cc: lvenanci@redhat.com Cc: riel@redhat.com Cc: xiaolong.ye@intel.com Link: http://lkml.kernel.org/r/20170517105350.hk5m4h4jb6dfr65a@hirez.programming.kicks-ass.net Signed-off-by: Ingo Molnar mingo@kernel.org Signed-off-by: Raphiel Rollerscaperers rapherion@raphielgang.org Signed-off-by: DennySPB dennyspb@gmail.com
[FIX] website, *: allow to re-edit company team snippet images
*: website_sale
Since 1, it was not possible to edit a company team snippet image anymore as soon as the page was saved once. Indeed that commit added o_not_editable/contenteditable="false" on the parent column to make sure no text can be added in that column and contenteditable="true" on the images so that they are still editable (even though HTML-specs-wise adding contenteditable="true" on images probably does not mean much as images are self-closing tags, our editor understand that as the ability to edit the image anyway). That contenteditable="true" part is however removed when leaving edit mode... and was not restored upon entering edit mode again.
This fixes the problems with a specific JS patch, we'll review to see if better can be done in master.
Funny enough, that bug was actually gone in 15.0... by mistake. A recent bug fix actually reintroduced that isolated bug at 2 (by reintroducing the fact that images in a non-editable environment are not possible to edit). The 3 opened tickets this commit mentions were actually reported for 15.0 immediately after that, while the 14.0 being broken about this since the beginning apparently did not bother anyone.
Note: as a forward-ported fix, this also takes the opportunity to clean
a bit what was done at 3. (calling _super, no duplicated code,
adding comments, ...).
opw-3031217 opw-3032482 opw-3035289
closes odoo/odoo#104521
X-original-commit: 1636ba5ed2f8a284bef0930313a85cc3dc7cf072 Signed-off-by: Romain Derie (rde) rde@odoo.com Signed-off-by: Quentin Smetz (qsm) qsm@odoo.com
Introduce initial support for streaming YAML input
Thanks to the new streaming text encoder and YAML chunker, we've finally achieved the first working implementation of streaming YAML input!
Besides the awful hackishness of the implementation that I've written about at length in the comments, the main limitation of this first pass is that YAML streaming only works when format detection is bypassed.
My current thinking is that instead of returning a String, the chunker can return a richer "Chunk" that includes both the string content and a marker indicating whether the root of the document is a scalar, sequence, or mapping. It should be pretty easy for the format detector to take advantage of that, I just hope it doesn't complicate the chunker too much more. The other possibility would be to parse the first chunk with serde_yaml and somehow have it tell us the root type, but that would probably require a custom Deserialize impl that I don't feel like writing.
Brimdemons & Lobstrosities drop (slightly) useful organs (#70546)
Goliaths, Legions, Watchers, and (as of recently) Bileworms all drop something vaguely useful when they die. Brimdemons and Lobstrosities do not. This PR aims to fix that, so that there's at least some vague benefit to hunting them.
In this case it takes the form of organs you get when you butcher them, similar to the regenerative core from Legions. As they're similar to the regenerative core, I modified the regenerative core to extend from a new common "monster core" typepath which these two new organs also extend. Like the regenerative core, both of these items do something when used and something slightly different if you go to the effort of having someone implant them into your body. They also decay over time, and you can use stabilising serum to prevent this from happening.
butcherbeasts.mp4
The Rush Gland from the Lobstrosity lets you do a little impression of their charging attack, making you run very fast for a handful of seconds and ignoring slowdown effects. Unlike a lobstrosity you aren't actually built to do this so if you run into a mob you will fall over, and if you are doing this on the space station running into any dense object will also make you fall over (it shouldn't make you too much of a pain for security to catch). The idea here is that you use this to save time running back and forth from the mining base.
The Brimdust Sac from the Brimdemon covers you in exploding dust. The next three times you take Brute damage some of the dust will explode, dealing damage equal to an unupgraded PKA shot to anything near you (but not you). If you do this in a space station not only is the damage proportionally lower (still matching the PKA), but it does effect you and also it sets you on fire. You can remove the buff by showering it off. The idea here is that you use this for minor revenge damage on enemies whose attacks you don't manage to dodge.
crabrush.mp4
If you implant the Rush Gland then you can use it once every 3 minutes without consuming it, and the buff lasts very slightly longer. It will automatically trigger itself if your health gets low, which might be good (helps you escape a rough situation) or bad (didn't want to use it yet).
smogchamp.-.Made.with.Clipchamp.mp4
If you implant the Brimdust Sac then you can use it once every 3 minutes to shake off cloud of dust which gives the buff to everyone nearby, if you want to kit out your miner squad. The dust cloud also makes you cough if you stand in it, and it's opaque. If you catch fire with this organ inside you and aren't in mining atmosphere then it will explode inside of your abdomen, which should probably be avoided, resultingly it is very risky to use this on the space station.
got the scroll behavior for hands working the way I want to essentially. however we still need to animate it. I'm thinking that I'll just do the most straightforward thing because it should be quick. However I suspect that we'll want to make it work for when the screen is resized cause it might look wonky
New Creep, new Pixelscene, various balance changes
Fixed Weak Hisii Shotgunners not jumping into minecarts Fixed Hisii Shotgunners occasionally turning into their weaker versions in minecarts Fixed Ceiling Fungus needing air to survive Red Sand now absorbs blood to grow Reduced Sentry Damage in earlier parts of the game Sigificantly reduced Sentry's range, he should now play a slightly different role than sniper by requiring a closer encounter but having better stats to cut through Nerfed wand dropped by Pandora's Chest on normal difficulty Mini Drones in earlier parts of the game are now more vulnerable to projectile damage Magic Devourer's are now more vulnerable to projectile & explosive damage Added 1 new pixelscene for Coal Pits, demonstrating Red Sand growing when fed Blood New creep: Smoking Fungus
feat: add vercel deploy support & simplify the entire setup (#66)
sanity/create before merging But you can use this button until then:

When I tried running this earlier today this is what I saw:

logs

I would've loved to have time to give the docs and readme some love. But for now priority 1 was to get it functional and automated. More automation makes it more realistic we'll be able to keep it up to date.
Quick list over changes that happened to https://github.com/sanity-io/sanity-template-nextjs-blog-comments earlier today, and what's proposed to https://github.com/sanity-io/sanity-template-nextjs-landing-pages in this PR:
- Build pipeline based on environment variables all the way, working locally, the CI jobs and the deploys to Vercel.
- A CI workflow that builds both Next.js and Studio to block PRs coming in.
- A connected live deploy to the template repos, providing ever green live demos that also serves as a second line of defense should the CI fail to detect a faulty dependency update.
- The templates have two datasets. When working locally and testing PR preview links you can mess around without breaking or "uglifying" the live demos.
- Renovate is configured to use our new
preset,
including a brand new one for Studio v2 that silences React 18 update
PRs until the Studio team gives us the go-ahead. And one for pinning
our
external github action workflows to commit SHA1's so bad actors can't
mutate a workflow and have it do something else, like stealing our
NPM_TOKEN. - If you forget to run
npx prettier --write .before you push your changes a friendly bot will fix it for you instead of giving your PR a failed check blocking you from merging.
Signed-off-by: Cody Olsen stipsan@gmail.com Co-authored-by: Cody Olsen 81981+stipsan@users.noreply.github.com Co-authored-by: stipsan stipsan@users.noreply.github.com
Refactoring summary list for each service (#8)
DEFRA/water-abstraction-team#54
We wanted to make the layout for each repo consistent and relate things like jobs to the service they belong to. We then decided we'd report on 'apps' rather than just 'repos', as that is what is running on a server and which 'the service' is dependent on.
We tidied up the external services section, including adding the Charge Module API which we'd, though not in the existing /service-status page, should be. We also got them to return meaningful information.
All the calls for info are now robust. Even if all the other apps and external services were down the page would still display.
All this work meant some major refactoring of the ServiceStatusService(), for example, a single method for making HTTP requests to the other apps and services.
All of this is tested. To do this we needed to bring in Nock to mock our HTTP requests to the other services and proxyquire to allow us to stub our calls to child_process.exec().
** Thoughts on the current state
Looking at the tests we see a copious amount of work needed to mock web requests and system calls. We also have a range of scenarios. In our opinion, they are telling us that our service is doing too much. It is collecting data from different sources in different ways, which means it definitely doesn't just have a single responsibility.
It needs breaking up, which in turn means we can break up the tests and hopefully make them a damn sight less scary.
We didn't do those changes in this PR though, because we'd already clocked up more than 1000 changes, well beyond our working target of 100. So, we've agreed to merge and tackle the refactoring as a separate exercise.
** Rebuilding the package-lock.json
Because of how long this PR had been around and the fact it adds new dependencies, we ended up having major merge issues in the package-lock.json. We went for a 'delete-and-rebuild' approach but we know we shouldn't have 😳 .
Next time we'll endeavour to use npm install --package-lock-only which we recently learned is a command added to npm to help rectify the package-lock.json in these 'merge-hell' situations.
Co-authored-by: Stuart Adair 43574728+StuAA78@users.noreply.github.com Co-authored-by: Rebecca Ransome beckyrose200@aol.com Co-authored-by: Alan Cruikshanks alan.cruikshanks@gmail.com
many changes
science level design (beta) scientist boss fight area design librarian boss fight area redesign extra pieces for labs other stuff my brain cannot remember right now
cocci: make "coccicheck" rule incremental
Optimize the very slow "coccicheck" target to take advantage of incremental rebuilding, and fix outstanding dependency problems with the existing rule.
The rule is now faster both on the initial run as we can make better use of GNU make's parallelism than the old ad-hoc combination of make's parallelism combined with $(SPATCH_BATCH_SIZE) and/or the "--jobs" argument to "spatch(1)".
It also makes us much faster when incrementally building, it's now viable to "make coccicheck" as topic branches are merged down.
The rule didn't use FORCE (or its equivalents) before, so a:
make coccicheck
make coccicheck
Would report nothing to do on the second iteration. But all of our patch output depended on all $(COCCI_SOURCES) files, therefore e.g.:
make -W grep.c coccicheck
Would do a full re-run, i.e. a a change in a single file would force us to do a full re-run.
The reason for this (not the initial rationale, but my analysis) is:
-
Since we create a single "*.cocci.patch+" we don't know where to pick up where we left off, or how to incrementally merge e.g. a "grep.c" change with an existing *.cocci.patch.
-
We've been carrying forward the dependency on the *.c files since 63f0a758a06 (add coccicheck make target, 2016-09-15) the rule was initially added as a sort of poor man's dependency discovery.
As we don't include other *.c files depending on other *.c files has always been broken, as could be trivially demonstrated e.g. with:
make coccicheck make -W strbuf.h coccicheckHowever, depending on the corresponding *.c files has been doing something, namely that if an API change modified both *.c and *.h files we'd catch the change to the *.h we care about via the *.c being changed.
For API changes that happened only via *.h files we'd do the wrong thing before this change, but e.g. for function additions (not "static inline" ones) catch the *.h change by proxy.
Now we'll instead:
-
Create a / pair in the .build directory, E.g. for swap.cocci and grep.c we'll create .build/contrib/coccinelle/swap.cocci.patch/grep.c.
That file is the diff we'll apply for that - combination, if there's no changes to me made (the common case) it'll be an empty file.
-
Our generated *.patch file (e.g. contrib/coccinelle/swap.cocci.patch) is now a simple "cat $^" of all of all of the / files for a given .
In the case discussed above of "grep.c" being changed we'll do the full "cat" every time, so they resulting *.cocci.patch will always be correct and up-to-date, even if it's "incrementally updated".
See 1cc0425a27c (Makefile: have "make pot" not "reset --hard", 2022-05-26) for another recent rule that used that technique.
As before we'll:
-
End up generating a contrib/coccinelle/swap.cocci.patch, if we "fail" by creating a non-empty patch we'll still exit with a zero exit code.
Arguably we should move to a more Makefile-native way of doing this, i.e. fail early, and if we want all of the "failed" changes we can use "make -k", but as the current "ci/run-static-analysis.sh" expects us to behave this way let's keep the existing behavior of exhaustively discovering all cocci changes, and only failing if spatch itself errors out.
Further implementation details & notes:
-
Before this change running "make coccicheck" would by default end up pegging just one CPU at the very end for a while, usually as we'd finish whichever *.cocci rule was the most expensive.
This could be mitigated by combining "make -jN" with SPATCH_BATCH_SIZE, see 960154b9c17 (coccicheck: optionally batch spatch invocations, 2019-05-06).
There will be cases where getting rid of "SPATCH_BATCH_SIZE" makes things worse, but a from-scratch "make coccicheck" with the default of SPATCH_BATCH_SIZE=1 (and tweaking it doesn't make a difference) is faster (~3m36s v.s. ~3m56s) with this approach, as we can feed the CPU more work in a less staggered way.
-
Getting rid of "SPATCH_BATCH_SIZE" particularly helps in cases where the default of 1 yields parallelism under "make coccicheck", but then running e.g.:
make -W contrib/coccinelle/swap.cocci coccicheckI.e. before that would use only one CPU core, until the user remembered to adjust "SPATCH_BATCH_SIZE" differently than the setting that makes sense when doing a non-incremental run of "make coccicheck".
-
Before the "make coccicheck" rule would have to clean "contrib/coccinelle/.cocci.patch", since we'd create "+" and ".log" files there. Now those are created in .build/contrib/coccinelle/, which is covered by the "cocciclean" rule already.
Outstanding issues & future work:
-
We could get rid of "--all-includes" in favor of manually specifying a list of includes to give to "spatch(1)".
As noted upthread of 1 a naïve removal of "--all-includes" will result in broken *.cocci patches, but if we know the exhaustive list of includes via COMPUTE_HEADER_DEPENDENCIES we don't need to re-scan for them, we could grab the headers to include from the .depend.d/.o.d and supply them with the "--include" option to spatch(1).q
Signed-off-by: Ævar Arnfjörð Bjarmason avarab@gmail.com Signed-off-by: Taylor Blau me@ttaylorr.com
Bzzzz
Barry! Breakfast is ready!
Ooming!
Hang on a second.
Hello?
-
Barry?
-
Adam?
-
Oan you believe this is happening?
-
I can't. I'll pick you up.
Looking sharp.
Use the stairs. Your father paid good money for those.
Sorry. I'm excited.
Here's the graduate. We're very proud of you, son.
A perfect report card, all B's.
Very proud.
Ma! I got a thing going here.
-
You got lint on your fuzz.
-
Ow! That's me!
-
Wave to us! We'll be in row 118,000.
-
Bye!
Barry, I told you, stop flying in the house!
-
Hey, Adam.
-
Hey, Barry.
-
Is that fuzz gel?
-
A little. Special day, graduation.
Never thought I'd make it.
Three days grade school, three days high school.
Those were awkward.
Yeeting this file beyond existence
enjoy my commits boys and girls
cover-letter: IOMMUFD Generic interface
[ This has been in linux-next for a little while now, and we've completed the syzkaller run. 1300 hours of CPU time have been invested since the last report with no improvement in coverage or new detections. syzkaller coverage reached 69%(75%), and review of the misses show substantial amounts are WARN_ON's and other debugging which are not expected to be covered. ]
iommufd is the user API to control the IOMMU subsystem as it relates to managing IO page tables that point at user space memory.
It takes over from drivers/vfio/vfio_iommu_type1.c (aka the VFIO container) which is the VFIO specific interface for a similar idea.
We see a broad need for extended features, some being highly IOMMU device specific:
- Binding iommu_domain's to PASID/SSID
- Userspace IO page tables, for ARM, x86 and S390
- Kernel bypassed invalidation of user page tables
- Re-use of the KVM page table in the IOMMU
- Dirty page tracking in the IOMMU
- Runtime Increase/Decrease of IOPTE size
- PRI support with faults resolved in userspace
Many of these HW features exist to support VM use cases - for instance the combination of PASID, PRI and Userspace IO Page Tables allows an implementation of DMA Shared Virtual Addressing (vSVA) within a guest. Dirty tracking enables VM live migration with SRIOV devices and PASID support allow creating "scalable IOV" devices, among other things.
As these features are fundamental to a VM platform they need to be uniformly exposed to all the driver families that do DMA into VMs, which is currently VFIO and VDPA.
The pre-v1 series proposed re-using the VFIO type 1 data structure, however it was suggested that if we are doing this big update then we should also come with an improved data structure that solves the limitations that VFIO type1 has. Notably this addresses:
-
Multiple IOAS/'containers' and multiple domains inside a single FD
-
Single-pin operation no matter how many domains and containers use a page
-
A fine grained locking scheme supporting user managed concurrency for multi-threaded map/unmap
-
A pre-registration mechanism to optimize vIOMMU use cases by pre-pinning pages
-
Extended ioctl API that can manage these new objects and exposes domains directly to user space
-
domains are sharable between subsystems, eg VFIO and VDPA
The bulk of this code is a new data structure design to track how the IOVAs are mapped to PFNs.
iommufd intends to be general and consumable by any driver that wants to DMA to userspace. From a driver perspective it can largely be dropped in in-place of iommu_attach_device() and provides a uniform full feature set to all consumers.
As this is a larger project this series is the first step. This series provides the iommfd "generic interface" which is designed to be suitable for applications like DPDK and VMM flows that are not optimized to specific HW scenarios. It is close to being a drop in replacement for the existing VFIO type 1 and supports existing qemu based VM flows.
Several follow-on series are being prepared:
-
Patches integrating with qemu in native mode: https://github.com/yiliu1765/qemu/commits/qemu-iommufd-6.0-rc2
-
A completed integration with VFIO now exists that covers "emulated" mdev use cases now, and can pass testing with qemu/etc in compatability mode: https://github.com/jgunthorpe/linux/commits/vfio_iommufd
-
A draft providing system iommu dirty tracking on top of iommufd, including iommu driver implementations: https://github.com/jpemartins/linux/commits/x86-iommufd
This pairs with patches for providing a similar API to support VFIO-device tracking to give a complete vfio solution: https://lore.kernel.org/kvm/20220901093853.60194-1-yishaih@nvidia.com/
-
Userspace page tables aka 'nested translation' for ARM and Intel iommu drivers: https://github.com/nicolinc/iommufd/commits/iommufd_nesting
-
"device centric" vfio series to expose the vfio_device FD directly as a normal cdev, and provide an extended API allowing dynamically changing the IOAS binding: https://github.com/yiliu1765/iommufd/commits/iommufd-v6.0-rc2-nesting-0901
-
Drafts for PASID and PRI interfaces are included above as well
Overall enough work is done now to show the merit of the new API design and at least draft solutions to many of the main problems.
Several people have contributed directly to this work: Eric Auger, Joao Martins, Kevin Tian, Lu Baolu, Nicolin Chen, Yi L Liu. Many more have participated in the discussions that lead here, and provided ideas. Thanks to all!
The v1/v2 iommufd series has been used to guide a large amount of preparatory work that has now been merged. The general theme is to organize things in a way that makes injecting iommufd natural:
-
VFIO live migration support with mlx5 and hisi_acc drivers. These series need a dirty tracking solution to be really usable. https://lore.kernel.org/kvm/20220224142024.147653-1-yishaih@nvidia.com/ https://lore.kernel.org/kvm/20220308184902.2242-1-shameerali.kolothum.thodi@huawei.com/
-
Significantly rework the VFIO gvt mdev and remove struct mdev_parent_ops https://lore.kernel.org/lkml/20220411141403.86980-1-hch@lst.de/
-
Rework how PCIe no-snoop blocking works https://lore.kernel.org/kvm/0-v3-2cf356649677+a32-intel_no_snoop_jgg@nvidia.com/
-
Consolidate dma ownership into the iommu core code https://lore.kernel.org/linux-iommu/20220418005000.897664-1-baolu.lu@linux.intel.com/
-
Make all vfio driver interfaces use struct vfio_device consistently https://lore.kernel.org/kvm/0-v4-8045e76bf00b+13d-vfio_mdev_no_group_jgg@nvidia.com/
-
Remove the vfio_group from the kvm/vfio interface https://lore.kernel.org/kvm/0-v3-f7729924a7ea+25e33-vfio_kvm_no_group_jgg@nvidia.com/
-
Simplify locking in vfio https://lore.kernel.org/kvm/0-v2-d035a1842d81+1bf-vfio_group_locking_jgg@nvidia.com/
-
Remove the vfio notifiter scheme that faces drivers https://lore.kernel.org/kvm/0-v4-681e038e30fd+78-vfio_unmap_notif_jgg@nvidia.com/
-
Improve the driver facing API for vfio pin/unpin pages to make the presence of struct page clear https://lore.kernel.org/kvm/20220723020256.30081-1-nicolinc@nvidia.com/
-
Clean up in the Intel IOMMU driver https://lore.kernel.org/linux-iommu/20220301020159.633356-1-baolu.lu@linux.intel.com/ https://lore.kernel.org/linux-iommu/20220510023407.2759143-1-baolu.lu@linux.intel.com/ https://lore.kernel.org/linux-iommu/20220514014322.2927339-1-baolu.lu@linux.intel.com/ https://lore.kernel.org/linux-iommu/20220706025524.2904370-1-baolu.lu@linux.intel.com/ https://lore.kernel.org/linux-iommu/20220702015610.2849494-1-baolu.lu@linux.intel.com/
-
Rework s390 vfio drivers https://lore.kernel.org/kvm/20220707135737.720765-1-farman@linux.ibm.com/
-
Normalize vfio ioctl handling https://lore.kernel.org/kvm/0-v2-0f9e632d54fb+d6-vfio_ioctl_split_jgg@nvidia.com/
-
VFIO API for dirty tracking (aka dma logging) managed inside a PCI device, with mlx5 implementation https://lore.kernel.org/kvm/20220901093853.60194-1-yishaih@nvidia.com
-
Introduce a struct device sysfs presence for struct vfio_device https://lore.kernel.org/kvm/20220901143747.32858-1-kevin.tian@intel.com/
-
Complete restructuring the vfio mdev model https://lore.kernel.org/kvm/20220822062208.152745-1-hch@lst.de/
-
Isolate VFIO container code in preperation for iommufd to provide an alternative implementation of it all https://lore.kernel.org/kvm/0-v1-a805b607f1fb+17b-vfio_container_split_jgg@nvidia.com
-
Simplify and consolidate iommu_domain/device compatability checking https://lore.kernel.org/linux-iommu/cover.1666042872.git.nicolinc@nvidia.com/
-
Align iommu SVA support with the domain-centric model https://lore.kernel.org/all/20221031005917.45690-1-baolu.lu@linux.intel.com/
This is about 233 patches applied since March, thank you to everyone involved in all this work!
Currently there are a number of supporting series still in progress:
-
DMABUF exporter support for VFIO to allow PCI P2P with VFIO https://lore.kernel.org/r/0-v2-472615b3877e+28f7-vfio_dma_buf_jgg@nvidia.com
-
Start to provide iommu_domain ops for POWER https://lore.kernel.org/all/20220714081822.3717693-1-aik@ozlabs.ru/
However, these are not necessary for this series to advance.
This is on github: https://github.com/jgunthorpe/linux/commits/iommufd
v4:
- Rebase to v6.1-rc3, include the iommu branch with the needed EINVAL patch series and also the SVA rework
- All bug fixes and comments with no API or behavioral changes
- gvt tests are passing again
- Syzkaller is no longer finding issues and achieved high coverage of 69%(75%)
- Coverity has been run by two people
- new "nth failure" test that systematically sweeps all error unwind paths looking for splats
- All fixes noted in the mailing list If you sent an email and I didn't reply please ping it, I have lost it.
- The selftest patch has been broken into three to make the additional modification to the main code clearer
- The interdiff is 1.8k lines for the main code, with another 3k of test suite changes v3: https://lore.kernel.org/r/0-v3-402a7d6459de+24b-iommufd_jgg@nvidia.com
- Rebase to v6.1-rc1
- Improve documentation
- Use EXPORT_SYMBOL_NS
- Fix W1, checkpatch stuff
- Revise pages.c to resolve the FIXMEs. Create a interval_tree_double_span_iter which allows a simple expression of the previously problematic algorithms
- Consistently use the word 'access' instead of user to refer to an access from an in-kernel user (eg vfio mdev)
- Support two forms of rlimit accounting and make the vfio compatible one the default in compatability mode (following series)
- Support old VFIO type1 by disabling huge pages and implementing a simple algorithm to split a struct iopt_area
- Full implementation of access support, test coverage and optimizations
- Complete COPY to be able to copy across contiguous areas. Improve all the algorithms around contiguous areas with a dedicated iterator
- Functional ENFORCED_COHERENT support
- Support multi-device groups
- Lots of smaller changes (the interdiff is 5k lines) v2: https://lore.kernel.org/r/0-v2-f9436d0bde78+4bb-iommufd_jgg@nvidia.com
- Rebase to v6.0-rc3
- Improve comments
- Change to an iterative destruction approach to avoid cycles
- Near rewrite of the vfio facing implementation, supported by a complete implementation on the vfio side
- New IOMMU_IOAS_ALLOW_IOVAS API as discussed. Allows userspace to assert that ranges of IOVA must always be mappable. To be used by a VMM that has promised a guest a certain availability of IOVA. May help guide PPC's multi-window implementation.
- Rework how unmap_iova works, user can unmap the whole ioas now
- The no-snoop / wbinvd support is implemented
- Bug fixes
- Test suite improvements
- Lots of smaller changes (the interdiff is 3k lines) v1: https://lore.kernel.org/r/0-v1-e79cd8d168e8+6-iommufd_jgg@nvidia.com
Cc: Niklas Schnelle schnelle@linux.ibm.com Cc: Matthew Rosato mjrosato@linux.ibm.com
Cc: Joao Martins joao.m.martins@oracle.com
Cc: Keqian Zhu zhukeqian1@huawei.com Cc: Shameerali Kolothum Thodi shameerali.kolothum.thodi@huawei.com
Cc: Eric Auger eric.auger@redhat.com Cc: Jean-Philippe Brucker jean-philippe@linaro.org
Cc: Daniel Jordan daniel.m.jordan@oracle.com
Cc: "Michael S. Tsirkin" mst@redhat.com Cc: Jason Wang jasowang@redhat.com
Cc: David Gibson david@gibson.dropbear.id.au
Cc: Alex Williamson alex.williamson@redhat.com Cc: Cornelia Huck cohuck@redhat.com Cc: kvm@vger.kernel.org
Cc: "Chaitanya Kulkarni" chaitanyak@nvidia.com Cc: Nicolin Chen nicolinc@nvidia.com Cc: Lu Baolu baolu.lu@linux.intel.com Cc: Kevin Tian kevin.tian@intel.com Cc: Yi Liu yi.l.liu@intel.com
Cc: Eric Farman farman@linux.ibm.com Signed-off-by: Jason Gunthorpe jgg@nvidia.com
Builds logic that manages turfs contained inside an area (#70966)
Area contents isn't a real list, instead it involves filtering everything in world This is slow, and something we should have better support for.
So instead, lets manage a list of turfs inside our area. This is simple, since we already move turfs by area contents anyway
This should speed up the uses I've found, and opens us up to using this pattern more often, which should make dev work easier.
By nature this is a tad fragile, so I've added a unit test to double check my work
Rather then instantly removing turfs from the contained_turfs list, we enter them into a list of turfs to pull out, later. Then we just use a getter for contained_turfs rather then a var read
This means we don't need to generate a lot of usage off removing turf by turf from space, and can instead do it only when we need to
I've added a subsystem to manage this process as well, to ensure we don't get any out of memory errors. It goes entry by entry, ensuring we get no overtime. This allows me to keep things like space clean, while keeping high amounts of usage on a sepearate subsystem when convienient
As a part of this goal of keeping space's churn as low as possible, I've setup code to ensure we do not add turfs to areas during a z level increment adjacent mapload. this saves a LOT of time, but is a tad messy
I've expanded where we use contained_turfs, including into some cases that filter for objects in areas. need to see if this is sane or not.
Builds sortedAreas on demand, caching until we mark the cache as violated
It's faster, and it also has the same behavior
I'm not posting speed changes cause frankly they're gonna be a bit
scattered and I'm scared to.
@Mothblocks if you'd like I can look into it. I think it'll pay for
itself just off reg_in_areas_in_z (I looked into it. it's really hard
to tell, sometimes it's a bit slower (0.7), sometimes it's 2 seconds
(0.5 if you use the old master figure) faster. life is pain.)
Less stupid, more flexible, more speed
Co-authored-by: san7890 the@san7890.com
Removes some useless code from welding helmet (#1363)
-
fuck you useless code
-
you cannot hide, useless code
fckin good enough, fuck this shit i hate css and html design/layout/ANYTHING, let me just fucking code some shit and manipulate data FUCK
Understanding Cycle Time in Software Development & its Importance
There’s a never-ending thirst for achieving a 100% productivity rate. Although that’s practically not possible, achieving one’s maximum productivity level without getting completely exhausted is a realizable goal - a goal that every software development team is striving to actualize.
In that pursuit, a metric is often left out of the equation or not given the due importance that it deserves. And that is cycle time.
Cycle time is the time a development team/a developer takes to complete the work assigned to them. It is calculated from the time the developer begins working on a task till it is completed and shipped to the customer.
For example, the cycle time starts when a developer picks up a work item such as creating a search feature. The cycle time ends when the search feature has been released and is available to the public.

When you measure your team’s cycle time, you not only have the superpower to identify bottlenecks but also to proactively resolve them. When done correctly they can indicate how efficient your software development team really is.
Shorter cycle times mean your development team’s progress is more efficient, smooth, and fast. And that translates to reduced time to market, a better product, and satisfied customers.
There are several tools out in the market today that can come in handy to measure cycle time. But if you want a rough calculation of the cycle time, you must simply calculate the difference of time between the start and end date of the process. Or, as the definition states, the difference in time between the developer’s start date to the ship date of the process.
For example, if a developer starts work on the 7th of April and they release the process on the 15th, the cycle time for this process is 8 days.
Cycle time is normally measured in no. of days.
The industry-standard way for measuring development cycle time is by tracking how long it takes for an item to go from the “In Progress” column in a Kanban Board tool to completed and shipped.
But with this method, the accuracy of your development cycle time goes out the window.
Because this is a process that heavily relies on manually updating the status of work items. And no matter what product or tool you use, we all know there's always that one member who forgets to update progress.
Here are some practical reasons why:
- Sometimes, the developer may have completed the task but may have forgotten to update its status.
- Quite often, there have been delays in changing the task’s status due to bottlenecks that go unnoticed.
- There have also been scenarios, though rare, where the developer might begin work on a task even before it’s added to the backlog.
In all these cases mentioned above, your report will have a huge gap that won’t get noticed and hence won’t be accurate. You simply can't blame the developers for these situations or breathe down their necks to make regular updates because they would have more pressing matters on their plate rather than to manually update their progress in the PM tool.
But, since these gaps in cycle times go unnoticed, it becomes next to impossible to identify areas for improvement or single out bottlenecks accurately.
So, how can you calculate software development cycle time accurately?
Combine the data from your project management tool along with the data generated in the tools your development team spends the most time in — Git!

So, here’s how we do it at Zepel.
We take the data from the developer's home turf - GitHub, GitLab, and Bitbucket. And when the first commit is made for a user story and the developers begin what they love doing - coding, we start calculating the cycle time.
We track the time throughout the different stages such as when a PR is issued, reviewed, and then merged. Finally, we end tracking only after the item has been released. This gives organizations a more accurate cycle time report.
Additionally, we identify bottlenecks and problem areas when a delay occurs. Here’s how👇🏼
Identifying bottlenecks in the earlier stages of development can help proactively resolve them and thereby improve the development process.
But how does cycle time help you do this?
For instance, you have planned a release on the 15th of April and the work begins on the 1st of April. But the work does not get completed on the 15th. The developer(s) working on the feature completes it only on the 20th.
Of course, the cumulative flow diagram of this release will show you the days when your team’s productivity wasn’t that great. It could be possible bottlenecks.
But if you wish to identify bottlenecks, you must measure the cycle time of each stage in the development process. That is, keep an eye on the time taken between the first commit and the PR opened, the time taken from PR opened to PR reviewed, and the time from PR merged to release.
For example, say you’ve planned a release on the 15th of April and the developer(s) makes the first commit on the 1st of April. Now, you know if a PR isn’t issued by the 10th, it’s likely to get delayed. If there’s a delay, then you can identify and resolve the bottleneck immediately.
So, whenever there is a considerable delay in any one of these stages, then that stage likely has a bottleneck that needs immediate attention and resolving to be done.
Zepel is one of the most developer-friendly project management tools with deep git integrations at its heart. It lets you update the progress of your tasks automagically based on your Git workflow, update teammates on Slack, and get accurate, real-time cycle time reporting so you can improve your software development process.

If you're on the lookout for a project management tool that will make the software development process easy for your team, try Zepel. :)
How to get Fitbit data into a Mobile App
Do you have any experience in getting Fitbit sensor Details to your Mobile App?
In this article, I'll show you how to use the Fitbit API to fetch Fitbit details into mobile apps.

Fitbit is a consumer electronics and fitness firm based in the United States. It develops wireless- enabled wearable technologies, such as physical fitness monitors and activity trackers, as well as related software. Fitbit tracks people's activity, diet, weight, and sleep to help them get in shape, remain motivated, and show how minor changes can have a significant impact.

Developers can use the Fitbit API to interact with Fitbit data in their own apps, products, and services. The API provides the majority of the read and write methods required to support your app.
One of my clients requested that I transfer Fitbit account information to his mobile app. He also requested that users who log into his app should receive all the available data from the Fitbit API. He would like to add people's day events to his app in order to suggest activities and provide health results to his users.
The client is provided a link to the Fitbit API. To access all of the information on a Fitbit, we must first create an application for it by filling out the form below.

After successfully creating the application I tried to get Auth from Fitbit, but I received an Error.
Because of the reason for that error in the Fitbit Application, we need to give the correct redirected URL. After several attempts, I managed to successfully retrieve the data from Fitbit. When we access the Fitbit API, we can choose what we need from a checkbox menu.
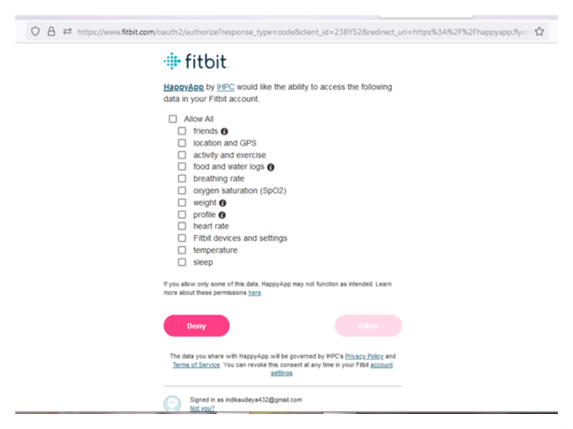
I checked to Allow All because I need my app to get all of the data. After everything is checked, we have to enter a code of the app we created in the API Debug menu of Fitbit. We have to do this ⬇️ to obtain the token.

After inputting all of the information, I must ensure that the data was received accurately. I tried several API testing softwares before discovering the API Tester mobile app. It has all of the features that a developer requires to work with APIs, so I can finish my work without needing a computer. I can test any kind of API, such as REST, GraphQL, WebSocket, SOAP, JSON RPC, XML, HTTP, and HTTPS, on the move from anywhere in the world, which greatly boosts my productivity.
Finally, we can use API Tester to send a GET request with the
endpoint URL and Authorization Header obtained during the token creation step. The Play button in the upper right corner brought up the Response screen, which is very user- friendly and displays all values. There is an option to switch between the Request and Response screens. Also, if necessary, we can share the response by hitting on the share icon.

After the work is done with the API Tester, we can send requests to the Fitbit through the Application we created. Then, in the android app, I successfully obtain Clients' required values as JSON.
Overall, I was able to successfully test the Fitbit API with the help of the API Tester. API Tester is a feature-rich mobile API client that can make the life of a developer easier. It provides a simple yet powerful interface with the ability to test APIs and submit requests of various methods.
hope you guy, this article will be helpful to you 🤗
Agile Meetups to Level Up Your Game (full list)
You hear about Agile all the time but did you already dive deep into the subject of how to truly utilize it? If not, here’s your chance. We’ve hand selected the top six meetup videos that are revolving around this topic. Enjoy!
40 Agile Methods in 40 Minutes | Craig Smith
With 66% of the world using Scrum as their predominant Agile method, this session will open up your eyes to the many other Agile methods and frameworks in the world today. For many, Agile is a toolbox of potential methods, practices and techniques, and like any good toolbox it is often more about using the right tool for the problem that will result in meaningful results. So join Craig on this rapid journey to look at the universe of Agile approaches and add some extra tools into your toolkit.
Improving Performance of Teams Using Statistical Analysis | Naresh Jain & Sriram Narayan
Large-scale software development generates a lot of data when teams use tools like Jira or Azure Devops. We could analyze the data with statistical tools and techniques in order to understand how to improve delivery performance. Naresh and Sriram have been attempting this at one of their clients. In this talk, they’ll share the techniques they used and the lessons they have learnt so far.
Agile Recruitment: The Missing Step In Your Transformation | Jakub Jurkiewicz
If we want to build agile organizations we need to recruit with agility in mind! If we care about people and interactions, we should create space for people to shine and where people can collaborate. What if the candidate does not fit any of our boxes? How could we respond to that and embrace this opportunity? What about hiring for culture-fit? Or is culture-add even more important? What could happen if we redesign our recruitment processes looking through the lenses of agile values and principles? In this talk we will explore how agility could help us shift the conversations in the recruitment processes, and how we could start recruiting for culture-add and hire people that will accelerate our agile transformations.
Spurring Growth with an Agile Culture | Ramkumar Venkatesa
Startups have been and will be a big factor in powering India to be a $5 trillion economy. Startups have a need to grow the customer base, product offerings, scale their technology and grow the teams. Succeeding in all of these parameters in a rapidly evolving environment is what makes startups successful. Agility enables startups to conquer these challenges. An agile culture is very important for successful Agility. The 3 pillars of building such a culture are alignment of goals, decentralized decisioning to attain those goals and a continuous feedback loop on decisions’ outcomes.
Don’t Bulldoze the Swamp for Agile | Steve Adolph
Large-scale agile transformations do not have a good track record with reportedly up to 70% falling far short of their goals. From a biological perspective, many agile transformations are like taking a bulldozer to a wild, diverse ecosystem. While we may create a consistent Way of Working, the transformation bulldozer often results in a monoculture, a weakened ecosystem that cannot adapt and innovate. Of course, to work together, especially at scale, we cannot just let our enterprise ecosystem grow wild because we need consistency to collaborate and coordinate. We can resolve this dilemma by taking a page from Socio-Technical systems for a more sustainable transformation. We introduce five principles for the “Greening” of the Agile Transformation that sustains and grows our capability to innovate while creating needed alignment and consistency.
Agile Transformation or Just Another Restructure | Terry Haayema
Is your Agile transformation just another restructure? Is everyone being shuffled around into Tribes? Villages? Crews? Are people reporting horizontally into Chapters? Is there talk of how we need to go faster? Were decisions made behind closed doors? Was the focus on structure as if that will change everything?
Consultants engaged who created lots of PowerPoint presentations with lovely motherhood statements about how our people are our greatest asset and the new structure will break down silos and allow us to go faster? Then it’s announced, teams are shuffled around into squads, tribes, chapters, etc.. As the transformation builds up speed, everyone gets some training and there is a massive amount of change management comms, presentations, and events. Big up front plans,… Big bang change,… Heavy Change Management,… Does that sound like a waterfall? In this talk we’ll discuss a better way by actually being agile about the way we approach agile!
The 5 Best Crypto Exchange Scripts to keep a look in 2023
Blockchain technology is rapidly growing and provides higher business opportunities to business people. In this present modern world, cryptocurrency has been a familiar one and crypto-related businesses are prominent that could reap a high profit. Higher usage of cryptocurrencies also expands the traffic of cryptocurrency exchanges.

Since the evolution of cryptocurrency, they have been consistently moving towards a profitable zone. On seeing this, many people are interested to invest their money and time in cryptocurrency to have their passive income.
This continuous growth of the crypto industry for the past decade has attracted entrepreneurs and business startups to launch their own cryptocurrency exchange to have a long time revenue-generating business.
If you’re one of the business startups having an ideal solution to build your own Cryptocurrency Exchange Business, then this article is especially for you. To start a successful crypto exchange business, choosing the correct path could make with the right procedures can make you launch an effective crypto exchange platform.
Let’s discuss in deeper about this via the article…
To launch a crypto exchange there are various methods, but picking the best method can be helpful for you in different ways. Cryptocurrency Exchange Script is the best solution to launch a crypto exchange business.
Cryptocurrency Exchange Script is a pre-configured software from which business startups can build a crypto exchange similar to any of the popular trading platforms in the world effectively. This software script also holds all the advanced trading features and essential security functionalities that an exchange should possess.
With the help of this crypto exchange script, you can launch your desired Crypto exchange within a very short time which is considered a highly beneficial factor. These exchange scripts also support all the familiar crypto coins such as Bitcoin, Ethereum, Dogecoin, etc…
The most benefit of buying a crypto exchange clone script is, 100% customizable where you can customize the design, theme, name, logo, trading features, security options, and add-ons based on your business requirements. This software script is already designed, developed, tested and ready for deployment.
The only thing from your side is to buy your customized desired script from a reputed and experienced solution provider and deploy it on your server.
Now you could have an idea about the Cryptocurrency Exchange Script. Now, lets’ see about the best exchange scripts that could be prominent in 2023.
- Binance Clone Script
- Coinbase Clone Script
- Wazirx Clone Script
- Paxful Clone Script
- Remitano Clone Script
Binance is considered to be the most popular cryptocurrency exchange platform at present, because of its advanced trading features and security options they provide. This exchange also supports multiple payment methods and the most notable thing is that charge a very low transaction fee when compared to another exchange platform. It also has its native token(BNB).
If you’re attracted to Binance exchange, then you can launch your exchange like Binance with the premium Binance Clone Script that consists all the inbuilt features and security options that Binance have. Also, you could customize the software by adding or removing the features.
Coinbase is a USA-based cryptocurrency exchange that is familiar all around the world. This exchange is highly suggested for the newbie in crypto trading because Coinbase provides a user-friendly interface which is simple and easy for new traders. Another attractive thing about Coinbase is they not only accept cryptocurrencies but also allow fiat currencies and allow to buy and sell coins using credit and debit cards or bank accounts.
Coinbase Clone Script is pre-made software that is a replica of the original Coinbase exchange consisting of multi-level security options and features. Also, customization can be made as per you’re business concepts.
Wazirx is an Indian-based P2P cryptocurrency trading platform with an automated engine. One of the leading cryptocurrency exchange platforms that consist of around 10 million active users. Wazirx also has its own Wazirx Token (or) WRX Coins. They also provide a low transaction fee. At present, lots of people prefer the Wazirx platform for trading.
Likewise, Wazirx Clone Script is an end-to-end customizable software that consists of all the features and functions of the original Wazirx platform, where you can add or remove the features and options.
Paxful is a USA-based leading Peer-2-Peer crypto exchange platform for the past several years. Paxful provides various payment methods for their users to buy and sell cryptocurrencies. Users’ are mostly from UAE, Pakistan, India, Malaysia and so on. Paxful is one of the trusted platforms that offer the buyer and sellers to communicate directly to buy or sell digital currencies.
Similarly, Paxful Clone script is concerned, this exchange script consists of all the inbuilt features and security functions of the original Paxful exchange.
Remitano is a familiar peer-2-peer cryptocurrency exchange with providing a safe and secure transactions for millions of active users. Remitano accepts multiple crypto coins such as Bitcoin(BTC), Ethereum(ETH), Tether(USDT), Litecoin(LTC), Ripple(XRP) and many other crypto coins. Also allows you to place the ad and earn a certain amount for this placement.
Remitano Clone Script is a pre-made software that provides all the essential features of the original platform that works exactly the same as Remitano. Likewise, customization is available as per your business concepts.
Trading and security features of a platform are the first thing that is noticed by the user when they are looking to sign up. So providing advanced security and the best features is the most required to run a successful crypto exchange platform.
Trading Features:
- Integrated IEO Module
- Advanced Trading Engine
- Liquidity API
- Margin & Futures Trading
- Payment Gateway Integration
- Cryptocurrency Wallet Integration
- Referral Programs
- Multi-Language Support
- Trading Bot
- Admin Console
Security Features:
- HTTPS authentication
- KYC/AML Verification
- Jail login
- Data encryption
- Two-factor authentication
- SQL injection prevention
- Anti Denial of Service(DoS)
- Cross-Site Request Forgery(CSRF) protection
- Server-Side Request Forgery(SSRF) protection
- Anti-Distributed Denial of Service
Final Words
To be honest, there are a lot of crypto exchange script providers in this crypto marketplace who are providing the solutions. However, in this competitive market, choosing the best one is the most important thing to be considered. And so, have great market research by considering your business factors and requirements and choose the top-notch Cryptocurrency Exchange Script provider to build your exclusive crypto exchange business.
An experienced and reputed script provider can support you in all the ways to build your desired crypto exchange business in a professional way at an affordable price. So choose such a provider and benefit from your crypto business.
WordPress.com vs. WordPress.org – The Differences & Which To Choose
👉 Original Blog Post : Link
Are WordPress.com and WordPress.org the same? It’s a question that on the surface seems so obvious, that many people don’t even think to ask it, let alone consider the answer. The truth is that those three little letters after the period make a huge difference, and could impact the success of your website in the future.
So, what are the differences between WordPress.com and WordPress.org? Besides sharing the name ‘WordPress’ there are a number of significant differences to be aware of when choosing the platform you want to use for your website.
To make things as clear as possible, we’re going to cover all differences between WordPress.com and WordPress.org, starting with:
This is where people typically get confused. Both are called WordPress, yet aren’t the same.
The non-profit WordPress Foundation manages WordPress.org which is a self-hosted content management system (meaning that you can install it anywhere and buy your own domain to set up a site). Not only is it a self-hosted content management system, but it’s also the world’s leading content management system.
WordPress.com, on the other hand, is essentially the largest WaaS platform owned by Automattic, the company run by WordPress co-founder, Matt Mullenweg. It is powered by the WordPress.org open-source software.
In short, WordPress.com is a limited version of WordPress.org that has been intentionally simplified for a completely different demographic.
WordPress.org is open-source meaning that the main difference is:
- Hosting – You can either set up a server with a cloud provider like DigitalOcean, Linode or Vultr or using a shared hosting service
While some of the most notable limitations of WordPress.com include:
- No monetization through ads is possible (you are locked in to using the “official” WordPress.com advertising program)
- No plugin installation or updates on the free plan — bigger plans also have these limitations, just lighter
- You only get to choose one out of a few free themes if you’re on a free plan
- Customization of the appearance, features, and overall site is heavily limited
- The free plan doesn’t let you use Google Analytics
- You have to upgrade from the free plan if you want to use your domain without the WordPress.com subdomain
- No eCommerce features or integrated payment on the free plan
- No membership websites
There are plenty more limitations with WordPress.com, however, you have more responsibility with WordPress.org as a result. This should affect your decision on whether you should go with WordPress.com or WordPress.org.
Budget is always one of the first things you have to figure out when you’re building something. In this case, there are big differences between the pricing and costs of WordPress.com and WordPress.org, so to help you plan your budget better, we have broken down both solutions.
WordPress.com offers four different pricing plans that can be paid annually, upfront, or monthly.
Here’s a detailed pricing breakdown for WordPress.com
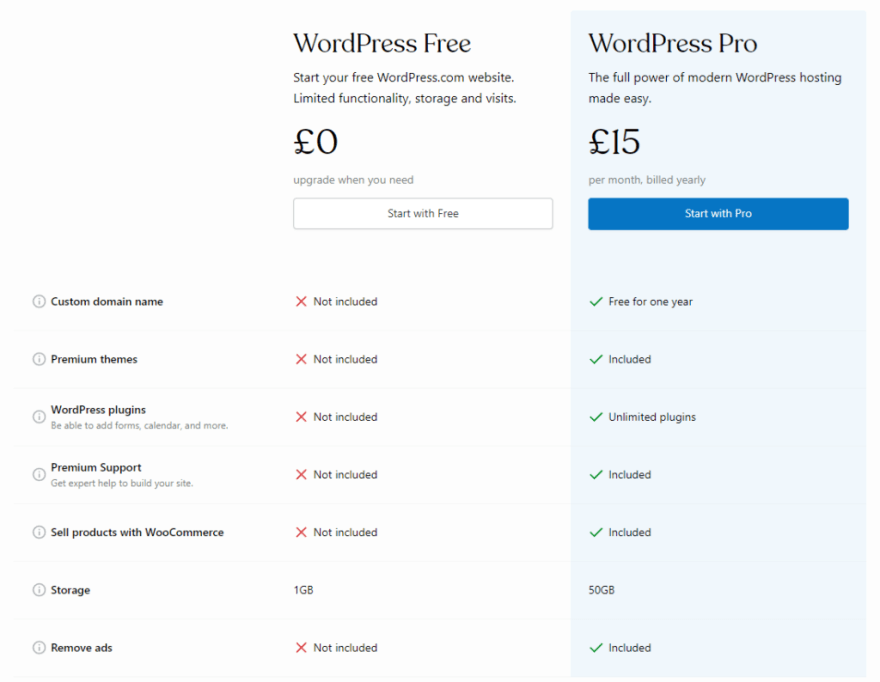
Besides these, WordPress.com does offer a free plan, and all you have to do is buy the domain. However, you will have their subdomain displayed e.g www.yourwebsite.wordpress.com.
When it comes to WordPress.org, it’s completely free to use. However, there are other costs that WordPress.org doesn’t cover, which WordPress.com covers for you.
- Hosting – You can either set up a server with a cloud provider like DigitalOcean, Linode or Vultr or using a shared hosting service
- Security — Depending on your hosting, you might need some premium security features or plugins that can cost up to $250 per year.
- Premium themes — there are free ones, but to get the most out of WordPress.org, you’ll probably want to go with premium themes. They usually cost up to $150 per year.
- Premium plugins — another optional thing, but if you’re serious about scaling your website fast, you will probably want to go with some premium plugins like Rank Math for SEO.
Both WordPress.com and WordPress.org have a learning curve, but which one is easier to overcome?
Since WordPress.org offers you a lot more freedom, you might frequently get lost if you’re a beginner. Whereas WordPress.com doesn’t have this issue. Their setup is more robust as you’re solely dependent on the plan you chose.
On the other hand, if you are a more advanced user, you’ll probably find your way faster with WordPress.org, as you’ll know exactly what you need to set up your intended site.
Setting up WordPress.com is a bit easier as it’s designed for blogging. Also, since it has far more limitations and doesn’t allow you to change many things you would normally be able to change on WordPress.org, fewer options mean it is easier to use.
Plugins are coded programs that serve the purpose of performing certain functions on your website, and they can be anything from payment integrations to a simple table of contents.
There are major differences in handling plugins on WordPress.com and WordPress.org so you must familiarize yourself with these to make your choice better.
WordPress.com doesn’t allow you to use any plugin upload or installation unless you’re on the Business plan ($300) even though the majority of plugins from WordPress databases (over 50,000) are free.
This again represents a huge limitation in controlling your website, but the benefit is that WordPress.com pretty much handles a lot of things for you. Whereas you’d need to install more plugins yourself on WordPress.org.
Speaking of WordPress.org, you have zero limitations when it comes to playing with plugins. You can install any plugin you want, free or premium, and configure it however you want.
Although both platforms have their advantages and disadvantages there’s really no question as to which is the best solution for any business that’s either already established or is planning on significant growth.
From the addons and plugins you can choose that allow you to integrate everything from payment portals to mailing lists, security to social media automation, to full control over your themes and website’s appearance, WordPress.org lets you have it all.
Thank You for reading till here. Meanwhile you can check out my other blog posts and visit my Github.
I am currently working on Stone CSS ( Github )
This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.
- 1. Dependency Injection
- 1.1. Preface
- 1.2. What's the Problem?
- 1.3. Library Example Description 📋
- 1.4. Tasks
- 1.5. Testing
- 1.6. Polymorphism 📋
- 1.7. Polymorphism Implementation 📋
- 1.8. Calling Abstract Method 📋
- 1.9. Command Line Application 📋
- 1.10. User Interface Problems 📋
- 1.11. Implementation in Library
- 1.12. Portability Problem
- 1.13. Distributing Testing Fixture
- 1.14. Inheritance
- 1.15. Object Creation 📋
- 1.16. No Polymorphism 📋
- 1.17. Dependency Injection
- 1.18. That's All for Now 🧑🏫
During this lesson, I want to conclude the object-oriented programming topic with a nontrivial example. I propose to learn more about object-oriented programming in the context of dependency injection design pattern. By pattern, I mean a programming archetype to solve a problem. It is a well-known and widely accepted pattern that is useful to be adopted in many scenarios. Those who have already heard about dependency injection may be concerned that this sounds like an introduction to an entirely different course but not a summary of this course. The concerns are justified, because many publications have already been written about dependency injection, and many frameworks exist on the market. There are also some terms used in this context like Inversion of Control, and Container we should be familiar with. The inversion of control we know from the previous lesson. To make the discussion transparent I will not use any framework. It allows for avoiding discussion about containers and reflection. Finally, you will learn the precise definition distinguishing object-oriented programming and dependency injection concepts. Let me stress that the main goal is not to be aware but to know how to use the dependency injection pattern. Especially I will pay attention to the differences between object-oriented programming and the dependency injection pattern. Again, this may sound puzzling, but I hope it will provide a basis for a better understanding of the object-oriented programming concept.
- Testing Program
- Dependence on Unknown Type
Before shipping to the production environment, the program should be tested. There are many testing methods that must be considered at the very beginning of commencing development. We also know that the layered architecture of the program could help to decouple parts and apply selectively the testing. Previously we concluded that abstraction could be very useful. Now we can conclude that a variety of test requirements thanks to abstraction allows for providing a polymorphic solution. Abstraction requires object-oriented programming concept implementation.
Layered program architecture and testing using a dedicated testing environment, for example, unit tests cause a side effect. That is a direct reference to some definition of concrete types that becomes impossible because the type can be located in the layer above or in an independent testing project. Finally, we cannot use the new operator to create an instance in the place where it should be used. Again object-oriented programming helps to solve it. To distinguish this programming pattern we will use the dependency injection term.
Let's assume that our task is to ship a library for an unknown in advance number of users. Additionally, we don't know where and how our library will be used. We can only assume that it will be a part of the logic layer. For the sake of simplicity, we are neglecting the existence of the data layer. It is not used and relevant in our example. The library examples to be investigated are located in the project DependencyInjectionLibrary. The first code snipped is called ConstructorInjection class. It contains several methods named Alfa, Bravo, Charlie, and Delta. Similar methods are gathered in the following example named PropertyInjection. In a production solution, we must provide only one implementation of the Alfa, Bravo, Charlie, and Delta methods using a constructor or property approach.
The first task you will face in a production environment is resolving a condition that makes the selection between the constructor and property injection pattern easier and more systematic. Depending on the expected features both have some advantages and disadvantages that should help to make a decision. Here it is worth stressing that there is also possible to merge both and provide a hybrid solution but this scenario is out of our lesson scope and you may implement it on your own.
The second task is testing our program, and especially our library before shipping it as a product. Unfortunately, testing doesn't guarantee that the final product is errorless but it could increase the chance that the algorithm and its implementation are as expected. To validate the implementation we have to face up the following tasks:
- make the text errorless according to the selected programming language
- testing the program to prove that the returned data is as expected, and
- check the program to prove that its behavior is as expected
Testing the program text against the selected programming language syntax and semantics is a design-time activity, required to prove that we have a program. Fortunately, this work is usually done by the compiler so we may safely skip this task for now.
Testing the returned data and behavior correctness is a run-time task and requires the execution of the program in a testing environment. The testing environment must resemble the production environment to make useful results. It is hard at the design time because the production environment is not defined yet. Usually, it is necessary to make the validity evaluation nondestructive. In other words, it should not disturb or even has an impact on the typical usage of the library in a production environment. Look at the library as a product.
This course is not focussed on testing therefore we can introduce many simplifications making our example especially readable for examination of a selected design pattern, I mean dependency injection and a better understanding of object-oriented programming. First, we can notice that our methods don't return any data so validation in this respect is not necessary.
In the ConstructorInjection and PropertyInjection classes, we have a few methods named Alfa, Bravo, Charlie, and Delta. For the sake of simplicity let's just assume that our job is to test only the sequence in which the methods are called. For testing purposes, I have applied a tracing mechanism. One of the benefits of this approach is the possibility to reuse it also in the production environment if needed. To test the sequence in which the methods are called each one calls an instance method of an object whose reference is assigned to the private TraceSource field. Because it is not about testing but about programming patterns the question, which will lead our discussion is how and where to create the object that is used for tracing purposes.
Consider two scenarios for testing this class. First, the classes could be used as a part of a hypothetical general-purpose library referred by in a console application. The second is unit testing. It is easy to guess that validation for these two examples must be implemented differently. So it is the first place where we must address polymorphism as a problem because the console application may use messages written on the screen to provide feedback and allow assessment of the implementation correctness by an application designer or user. For the unit testing, we must not use the user interface because it doesn't exist at all. Both test methods have been implemented and added to the design environment as independent projects called appropriately: DependencyInjectionUserInterface and DependencyInjectionTest. From this example, we can learn that our solution requires a polymorphic approach, I mean we need at least two independent implementations of the same functionality, namely tracing.
We may implement polymorphic solutions using abstraction, inheritance, and implementation. As I said previously, there are two examples but the first one I will use is the ConstructorInjection class. I used abstraction to define the type of the TraceSource field of the class. Its value is assigned while the class constructor is executed. In this language, we call it field of class but in general, it is just a variable, I mean value holder. The type of this variable is ITraceSource. Using F12 we can get the type definition. It is an interface that defines just one method called TraceData. The interface is an abstract definition. The interface construct is an abstract definition because it doesn't provide any implementation details and can be recognized as a contract between the class ConstructorInjection and any user of this class, that is any creator of this class. We know that the object referred to by this variable has the TraceData method implemented, and the signature of this method is defined by the mentioned interface. Finally, we are calling a method but we are not aware of its implementation details. At run time when we are talking about objects, all implementations must be defined in the place the object is created, but the implementations can be different depending on the needs of a creator. According to this contract, there are two clear roles. First is the interface user. In this case, it is the ConstructorInjection class. The second is the implementation provider, and in this case, it is a console application or a unit test. In this place, we are using the reference of abstract type but we know that to create any object a concrete class must be derived from this interface.
Here we can see that the TraceSource field contains a reference to an object, but its type has been declared as an interface offering one method. Here, however, based on the interface definition we indicate that the object must provide an implementation of the TraceData method, but again we should not assume how this operation works. As I said it is just a kind of contract. We only specify a formal declaration containing a formal list of arguments because we define only the header of the method called the method signature. As a result, the declaration is there, but it hides (or it rather doesn't provide) implementation details and that is why we call it an abstract declaration. This does not prevent you from using it and calling it, passing to it the current values of its arguments in accordance with the declared signature.
I'll come back to unit tests shortly, but now let's examine an example of tracing process implementation to be used by the console application. The result on the screen we can observe by running the console application. As you can see, the result is four messages displayed on the screen, which can then be used to determine the sequence of method calls and to diagnose manually the correctness of this sequence. This behavior is provided by a custom implementation of the interface. The object of this class is created and assigned to the constructor of the ConstructorInjection class. The question is if this solution is entirely based on an object-oriented programming paradigm. Let's analyze in detail all the code parts in concern. Here we have abstraction. To the parameter of the abstract type, we are assigning a reference to the object created using the class derived from the interface using inheritance. Concluding, everything looks compliant with the object-oriented programming concept. There is nothing special, nothing extraordinary compared with the object-oriented programming concept.
In this solution where the user interface is used for diagnostic purposes, we can indicate several important problems related to this implementation. In a production environment, such displaying of diagnostic information on the screen for the user may be confusing and useless because the end user doesn't know the correct sequence, doesn't know the meaning of these messages, or doesn't care about the diagnostic information - the program should be correct and that's it. Today, for the production environment, we usually use a graphical user interface. In this case, displaying several diagnostic lines of messages is not a good idea in general. Let's add that unit tests do not have UI support, so displaying anything to the user is useless. Summing up, we can see that the discussed solution is not practical for the production environment, although on-screen diagnostics has always been a favorite approach for novice programmers, because only lack of experience explains the thoughtless omission of the issue in which there are, for example, several thousand lines. Anyway, the example should be recognized only as another implementation of the testing stuff. It doesn't decrease applicability comparing it with a unit test and our discussion about polymorphism.
Let's return to the polymorphic problem we have. Just to recall, we need two independent implementations of the ITraceSource interface. One is for the command line application. The second is for unit testing purposes. Of course, we can implement all variants inside the library that will provide the appropriate functionality for each of the cases mentioned. To avoid using our imagination let me try to expand this example and implement the interface locally. I am creating MyClass which inherits the ITraceSource interface. Using the context menu we may implement this interface to create a concrete class that the ConstructorInjection class can use. In this case, the object used for the diagnostic purpose can be instantiated locally, and passing by the argument the trace engine may be omitted. To support variants the type of argument may be replaced by enumerations allowing for a selection of a variant predictable at design time. For sake of simplicity, this case is omitted. The code is kept as simple as possible. Of course in this case the defined class doesn't implement any actual functionality - it just throws the not implemented exception. I will try to prove shortly that it is a very bad solution.
This approach - I mean local implementation of the diagnostic functionality - is only possible if we could predict all behavior variants we will need in the future. The future time - that I have used in the previous sentence - suggests that it is impossible or at least impractical because I immediately think of a few other ideas on how such diagnostics can be implemented in a different way, for example saving diagnostic messages to a file, or maybe logging the diagnostic information to the cloud, and there is also a database that may be considered. Let's add that the implementation of the logging mechanism on the screen inside the library will result in the necessity to answer the next question: what technology to use, for example, console application as in the example, Windows Presentation Foundation, or Forms in case of Windows operating system. But in general, local implementation of selected scenarios at design time is devastating for portability ar run time because it requires that the technology exists on the target execution platform.
It is beyond the course scope but it is worth stressing now that the diagnostic information may be generated at run time for testing or maintenance purposes. If the main goal to create the diagnostic information is testing everything that is not necessary should be removed from the library to avoid shipping a code that is partially useless for the production environment. For example, the implementation of the interface ITraceSource that if defined in the code should be located outside of the library assembly to minimize its memory footprint and execution time. Before considering the local implementation of diagnostic information logging, first, we must answer the question of if this functionality is required in the production environment. Again, if the main purpose is to engage this functionality as the testing fixture we must avoid implementing it as part of the library to avoid shipping useless functionality to the end user. In this case, the local implementation should do nothing as in the example. Now we can use this class as the default implementation instead of throwing the argument null exception if the input attribute is null.
During the program execution phase, the expected algorithm must be implemented. This can only be ensured by creating objects from concrete types, so only objects with all implementation details can be instantiated. In the considered example for this interface, it is necessary to declare a new type that will provide this interface implementation. Using the navigation let's look for all references. On the list we get, we have a few suggestions, but let's choose the one that relates to the project of the previously launched sample console application. Here we see this relationship where the new type is defined with the use of the source type. We call this relationship inheritance, the source type is called the base type, and the newly created type we call the derived type. There are other terms, but I will use these consequently. In the newly created concrete class, all abstract declarations must be refined in such a way that the missing implementation details are provided. In our case, the block is missing in the TraceData method, which we add here to the signature of the method inherited from the interface. We call this process the abstraction implementation. As a side note, a block is a sequence of instructions separated by a semicolon - sometimes it is also called body for some reason.
In order for our example to be finished, it is still necessary to specify what specific object implemented the tracing functionality is to be used in the library. Previously, I used a very broad statement, namely: some object whose reference is assigned to a field. So now is a good time to clarify this statement. This field is initialized in the class constructor using the current value of this argument. The instantiation of an object of this class can be found again by using the navigation available in the context menu and looking for all references to this constructor. An object of this class is instantiated in the sample program and a reference to it is passed to the constructor of the library class from which the methods of its instance are called in the sequence. In this case, the reference to the created object becomes the current argument of the constructor.
In this example, we started with a polymorphism requirement that was shown as a problem to solve, and then we applied the object-oriented programming paradigm including abstraction, inheritance, and implementation to solve it. Well, as a result, use your imagination and consider the case where we have the console application only for testing purposes. In this case we don't have polymorphism at all. In this particular case, there is no diversity, the program always behaves the same. What's more, there is even no need to use a variant solution, because its behavior is not even parameterized. Is the use of the entire object-oriented programming engine redundant then?
Of course, answering this question we say no it is not a redundant approach because we must take into account the fact that the driving force behind our approach and the problem to be solved was the need to take into account polymorphism in future solutions, and not only in a specific solution, I meant in the library itself. The word "future" is the most important because it means that where the object is referenced, its type is unknown because its definition will be compiled later. And it doesn't matter if it's a few milliseconds later or years later. I named this pattern described here dependency injection to somehow terminologically distinguish the situations of using object-oriented programming to implement a potential polymorphism and using it to create variant local solutions. Concluding, in this scenario, we deal with the separation of concerns. One is the usage, and the second is implementation. Hence, shortly the dependency injection is a pattern where we are using unknown for some reason type that we replace by abstraction. Here the type is located in an independent assembly so cannot be referenced directly to avoid circular references between assemblies. Later, while discussing layered program architecture, we will learn the next example where direct access to the concrete type is impossible and must be replaced by abstraction. Shortly, the dependency injection is a pattern we must apply in any scenario where we cannot use the new operator in the place of use to create an object because the type is or shall be unknown for some reason.
And that's all for this episode, this lesson. Thank you for your time and I invite you to listen to the next lessons.
Update en
alaskan pipeline - might remove relevant content on extractives big black - removes a lot of relevant content related to products cialis - actual product name in healthcare cornhole - also drinking game creampie - too broad of a term (e.g., Boston creampie) dick - short name for people named Richard (e.g., Dick Durbin - US Senator) girl on - too broad of a phrase jelly donut - removes content related to actual donuts lolita - actual proper name for some individuals make me come - too broad of a phrase poof - too broad of a phrase (e.g., furniture or "poof, its gone") shrimping - too broad of a phrase (e.g., shrimping business impacted by climate change) snatch - too broad of a phrase (e.g., snatch my wallet) suck - too broad of a phrase (e.g., "embrace the suck") sucks - too broad of a phrase (e.g., "oh, that sucks") taste my - too broad of a phrase (e.g., I went to taste my soup and it was bad) tied up - too broad of a phrase (e.g., I'm tied up and can't make it) tongue in a - too broad of a phrase (e.g., tongue in a patient or beef tongue in a stew) viagra - actual product name in healthcare
Power Daggers on RoT units
Crimson Paladins, Dawnbreakers Angels Tears Interemptor Squad Inner Circle Cenobuim (and broken claws) all models Grave Wardens Mortus Poisoner Kakophoni Palatine Blade & Aquilae Phoenix Termy Sun Killer Huscarl Phalanx Warder Templar Brethren Gorgon Termy Medusan Immortals Iron Havocs Tyrant Siege Termy Atramentar Contekar Night Raptor Terror Squad Dark Furies Deliverers Mor Deythan Firedrakes Pyroclast Reaver Aggressor and Reaver Attack squads Gray Stalkers Gray Slayers Jorlund Hunter Varagyr Wolf Guard Ammitara Occult Khenetai Numerologist Sekhmet Fulmentarus Invictarus Suzerain (looks a bit messy due to currently all collectives, and every model is a character, but will only affect AL players. Might be able to be tidied up later) Locutarus Nemesis Destroyer Praetorian Breacher Dark Sons of Death Falcon's Claws Golden Keshig Ashen Circle Rampager Red Butchers Red Hand Destroyers