- Disaster recovery: More complex than you might think
- Reference numbers for disaster recovery
- Downtime tolerance matrix
- Systems with low tolerance for downtime and data loss
- Can I address downtime and data loss with just 2 nodes?
- Meeting downtime and data loss requirements
- Considering capacity with downtime and data loss addressed
- High tolerance for downtime
- High tolerance for data loss
- Sharded clusters
- Backup strategies
- Filesystem-based backup strategies
- Filesystem-based backup when using RAID
- Restoration caveats
- MongoDB tools for backup
In this problem we have provided you with a replica set that is corrupted. You will start out with a working primary, a corrupted secondary, and a working arbiter. Your goal is to recover the replica set by doing the necessary work to ensure the secondary has an uncorrupted version of the data.
Please download and extract the handouts. There are three data directories: one for the primary, secondary, and arbiter. On your guest VM, you will need to run mongods for each of these on ports 30001, 30002, and 30003. If you initially find that the mongod running on port 30002 is a primary, please step it down. To get the replica set up and running, each node should be launched as follows (note: the dbpath directory for each node is located within a subdirectory of each handout):
- Primary:
mongod --port 30001 --dbpath mongod-pri --replSet CorruptionTest --smallfiles --oplogSize 128 --nojournal
- Secondary:
mongod --port 30002 --dbpath mongod-sec --replSet CorruptionTest --smallfiles --oplogSize 128 --nojournal
- Arbiter
mongod --port 30003 --dbpath mongod-arb --replSet CorruptionTest --nojournal
For this problem, do not attempt to configure MongoProc's port settings. You may still configure the host setting. The corrupt data is in the data files found within the mongod-sec directory. Specifically, the testColl collection of the testDB database is corrupted. You can generate an error due to the corruption by running a .find().explain("executionStats") query on this collection (e.g. "use testDB; db.testColl.find().explain("executionStats")" to show the corruption error).
Bring the secondary back on line with uncorrupted data. When you believe you have done this, use MongoProc to test and, if correct, submit the homework
- Download Handouts
- Untar handouts
tar -xzvf mongod-pri.tar.gz
tar -xzvf mongod-arb.tar.gz
tar -xzvf mongod-sec.tar.gz
- Run mongod
mongod --port 30001 --dbpath mongod-pri --replSet CorruptionTest --smallfiles --oplogSize 128 --nojournal
mongod --port 30002 --dbpath mongod-sec --replSet CorruptionTest --smallfiles --oplogSize 128 --nojournal
mongod --port 30003 --dbpath mongod-arb --replSet CorruptionTest --nojournal
- Stop slave and remove data from mongod-sec directory
- Start slave, data will be synced from primary
You are running a service with a predictable traffic usage pattern. Every Monday the usage peaks at 100,000 reads/sec on your replica set at 17:00 UTC.
For each of the next four days, the peak is 2% higher than the previous day (so 102,000 reads/sec on Tuesday, 104,040 on Wednesday, 106,121 on Thursday, 108,243 on Friday) at 17:00 UTC each day. Saturday and Sunday see significantly reduced traffic, at peaks of 50,000. This pattern repeats each week.
You have nine servers that are evenly distributed across three data centers. The application uses a read preference of secondary. Each of the nine servers has been benchmarked to handle 24,000 reads/sec at its maximum capacity.
There is a further mandate to avoid exceeding 90% of available capacity, if at all possible, for performance reasons. If the application exceeds 90%, this must be reported and escalated to the executive level.
You have deployed the servers as follows:
- Data Center A: Primary, Secondary, Secondary
- Data Center B: Secondary, Secondary, Secondary
- Data Center C: Secondary, Secondary, Secondary
A failure occurs at 19:00 UTC on a Saturday when Data Center C becomes unavailable, along with its servers. Based on the description above, by when must you fix the issue in order to be sure you do not exceed the 90% capacity rule and cause escalations to happen?
Assumptions:
- The load is evenly distributed across all available secondaries, and redistributes itself shortlyafter the failure.
- The load does not deviate from the prediction.
- You cannot read from the primary.
- All assumptions here are reasonable. ;-)
Capacity on failure 24k2 + 24k3 = 120k, 90% of this capacity is 108k, then the answer is Friday.
- Before the peak on Sunday
- Before the peak on Monday
- Before the peak on Tuesday
- Before the peak on Wednesday
- Before the peak on Thursday
+ Before the peak on Friday
- Before the peak on next Saturday
Suppose you have a 3 member replica set with the primary in Data Center 2 (DC2) and two secondaries in Data Center 1 (DC1). You have set write concern at w=1.
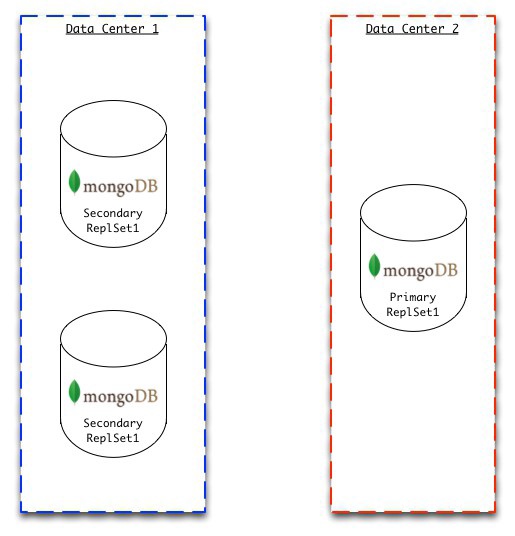
Now suppose that your application makes three writes to the primary. However, before these writes have been replicated to either of the secondaries, there is a network partition that prevents communication between DC2 and DC1. The partition lasts for 10 minutes. The application producing writes is able to see all three members of the replica set during the entire network partition between DC2 and DC1. No other problems with your system arise during this period.
Which of the following are true about the system during the period of the network partition?
+ The application will still be able to read data.
- The three writes to the primary before the network partition will be replicated to the secondaries when the partition ends.
+ The primary in DC2 will step itself down when the partition occurs.
- An election will occur when the partition ends.
+ The two secondaries will hold an election when the partition occurs.
+ The application will still be able to write while the partition is up.
- Only reads will be possible while the partition is up.
Suppose that last night at midnight you took a snapshot of your database with mongodump. At a later time, someone accidentally dropped the only collection in the database using db.collection.drop(). You wish to restore the database to the state it was in immediately before the collection was dropped by replaying the oplog.
Which of the following are steps you should take in order for this to be successful? Check all that apply.
- Prevent the writes that occurred before the backup from taking place.
+ Prevent any writes that occurred after the drop() command from being replayed.
+ Prevent the db.collection.drop() command in the oplog from being replayed.
This problem will be a hands-on implementation of the last problem.
The backupDB database has one collection, backupColl. Your system is backed up with a mongodump. After one of these, the server continued taking writes until someone (not you) ran the command:
db.backupColl.drop()
Your job is to put your database back into the state it was in immediately before the database was dropped, then use MongoProc to verify that you have done it correctly. You have been provided with a server directory in the backuptest.tar.gz file that includes your (now empty) data files, the mongodump file in backupDB.tar.gz, and a mongod.conf file. The conf file will set the name of your replica set to "BackupTest" and the port to 30001. Your replica set must have these settings to be graded correct in MongoProc. You may configure the host setting for MongoProc if necessary.
Use MongoProc to evaluate your solution. You can verify that your database is in the correct state with the test button and turn it in once you've passed.
This assignment is fairly tricky so you may want to check this stackoverflow question and answer. An alternative method to the stackoverflow response is using the "mongooplog" tool (there are several solutions to this problem).
If you run into the error with mongorestore "error applying oplog: applyOps: EOF", this issue has been fixed in MongoDB 3.0.4. At the time of this update, 3.0.4 is available for download as a release candidate (The 3.0.4-rc0 mongorestore binary for Ubuntu 14.04 can be downloaded here)
Tip: You may not need this, but if you are interested in updating an oplog's 'op' field for a document, it will complain if you increase the size the document (which it thinks is happening as an intermediate stage of an update), but you can do it anyway by simultaneously unsetting another field. For example, db.oplog.rs.update( { query }, { $set : { "op" : "c" }, $unset : { "o" : 1 } } ).
Tip #2: After restoring, you will find that you have 614800 documents in the collection.
- Download Handouts
- Untar handouts
tar -xzvf backupDB.tar.gz
tar -xzvf backuptest.tar.gz
- Run mongod with current db
mongod -f mongod.conf
- dump oplog to oplogD directory
mkdir oplogD
sc:new $ mongodump --port 30001 -d local -c oplog.rs -o oplogD
2016-04-09T19:37:49.302+0300 writing local.oplog.rs to
2016-04-09T19:37:51.141+0300 done dumping local.oplog.rs (701202 documents)- create separate restore dir and copy oplog for future restore
mkdir oplogR
cp oplogD/local/oplog.rs.bson oplogR/oplog.bson
- Login to mongodb and get drop command timestamp
sc:new $ mongo --port 30001
MongoDB shell version: 3.2.1
connecting to: 127.0.0.1:30001/test
BackupTest:PRIMARY>
BackupTest:PRIMARY> use local
switched to db local
BackupTest:PRIMARY> db.oplog.rs.find({"o": {"drop": "backupColl"}})
{ "ts" : Timestamp(1398778745, 1), "h" : NumberLong("-4262957146204779874"), "v" : 2, "op" : "c", "ns" : "backupDB.$cmd", "o" : { "drop" : "backupColl" } }
- Start separate instance without replset
mkdir backuptest2
cat >> mongod.instance.conf << END
port=30002
fork=true
logpath=./backuptest2/mongodb.log
dbpath=./backuptest2
smallfiles=true
END
mongod -f mongod.instance.conf- Restore backup to separate instance
$ mongorestore --port 30002 -d backupDB backupDB
2016-04-09T19:52:32.104+0300 building a list of collections to restore from backupDB dir
2016-04-09T19:52:32.105+0300 reading metadata for backupDB.backupColl from backupDB/backupColl.metadata.json
2016-04-09T19:52:32.105+0300 restoring backupDB.backupColl from backupDB/backupColl.bson
2016-04-09T19:52:35.110+0300 [#############...........] backupDB.backupColl 30.3 MB/52.5 MB (57.8%)
2016-04-09T19:52:37.287+0300 [########################] backupDB.backupColl 52.5 MB/52.5 MB (100.0%)
2016-04-09T19:52:37.287+0300 restoring indexes for collection backupDB.backupColl from metadata
2016-04-09T19:52:37.287+0300 finished restoring backupDB.backupColl (604800 documents)
2016-04-09T19:52:37.287+0300 done- Replay commands from oplog before 'drop backupColl'
sc:new $ mongorestore --port 30002 --oplogReplay --oplogLimit 1398778745:1 oplogR
2016-04-09T22:06:20.390+0300 building a list of dbs and collections to restore from oplogR dir
2016-04-09T22:06:20.390+0300 replaying oplog
2016-04-09T22:06:23.393+0300 oplog 16.5 MB
2016-04-09T22:06:26.394+0300 oplog 32.0 MB
2016-04-09T22:06:29.391+0300 oplog 48.0 MB
2016-04-09T22:06:32.392+0300 oplog 64.0 MB
2016-04-09T22:06:35.393+0300 oplog 80.4 MB
2016-04-09T22:06:38.394+0300 oplog 96.5 MB
2016-04-09T22:06:41.396+0300 oplog 108.7 MB
2016-04-09T22:06:41.484+0300 oplog 108.7 MB
2016-04-09T22:06:41.484+0300 done