{kind=link}
A multi-layer perceptron network for artificial text and character generation
CharNet is a multilayer perceptron network using a feed-forward network where each layer receives all previous layers as inputs.
CharNet acts as a humanly-readable example to show improvements compared to common multilayer perceptron models and RNNs for sequential data.
Various parameters are supported, most of them being switches, you can try to configure your own model.
To get started, clone this repository, import the charnet and execute it with your configuration. For a more in-depth tutorial, you can also follow the notebook in here or execute the notebook using a Cloud-GPU at Google Colaboratory.
A 3GB example dataset created out of all books found on the full books site can be downloaded in here.
A 500MB dataset based on the data from textfiles can be downloaded in here. This dataset is significantly more noisy.
Both datasets have been formatted to use a minimalistic character set.
A third, significantly smaller dataset, is a dataset containing all tweets by Donald Trump, as seen in here. Its only 5 Megabytes, contains links and is not formatted yet. It can be found in here.
Lastly there also is a dump of the linux kernel with removed comments which can be found in here. It hasnt been formatted either.
It is recommended to copy those datasets to your google drive to then use them in Google Colab if you are looking to try this project out.
| Parameter name | Description | Datatype | Default value |
|---|---|---|---|
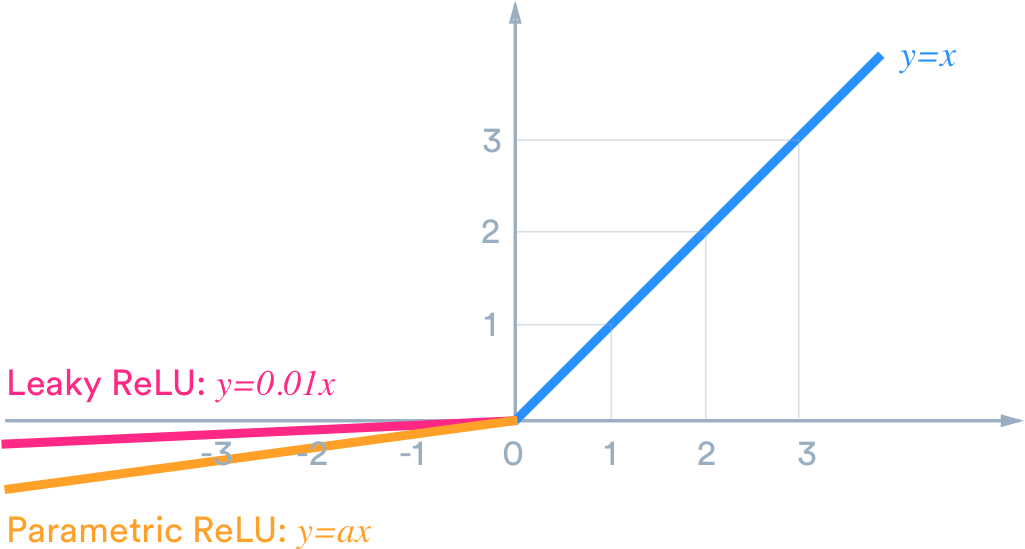
| leakyReLU | LeakyReLU is a rectifier function which can be used as an activation layer. See this graphic for more information. | Boolean | False |
| batchNorm | Batch Normalization is a technique that can be used in keras to achieve better results by normalizing the activations of the previous layer. | Boolean | False |
| trainNewModel | Specifies whether a new model should be trained or an old one should be loaded to continue training. | Boolean | True |
| repeatInput | Append the input layer to the input of every layer. | Boolean | True |
| unroll | When using a LSTM on a non-GPU device, LSTMs can be unrolled to reduce computational cost while increasing RAM cost drastically. | Boolean | True |
| splitInputs | If a large number of inputs is used, the inputs can be split to many perceptrons which all receive only part of the input. | Boolean | False |
| initialLSTM | Use an LSTM as the first layer after the input layer. LSTMs tend to have a better performance for sequence prediction, yet are against the idea of an MLP. | Boolean | False |
| inputDense | Adds a smaller layer in front of the hidden layers to reduce calculation. The number of neurons in it is equal to the number of inputs. | Boolean | False |
| splitLayer | Similar to splitInputs, layers can be split as well when they receive many inputs. This particular implementation also allows data to be fed from left to right of the model. It is highly discoured to use this parameter as it disables every form of parallelization. | Boolean | False |
| concatDense | Concatenate all previous layers to one big input layer for the next hidden layer. See model.png for more information. This is the main point of research of CharNet. | Boolean | True |
| bidirectional | If a LSTM is used, it can either be bidirectional or not. Bidirectional LSTMs tend to understand constructs better but also require twice the time to train and evaluate. | Boolean | True |
| concatBeforeOutput | If activated, all previous layers will be concatenated to one large layer to be fed into the output layer. See model.png for more information. | Boolean | True |
| drawModel | Draws a graphic as seen in model.png using keras' built-in functions to help visualize the networks architecture. | Boolean | True |
| gpu | Specifies whether a NVIDIA GPU is used or not. Using an NVIDIA GPU allows for massive optimizations in LSTM calculation. | Boolean | True |
| indexIn | If activated, indexes or labels are used as inputs instead of one-hot encoded labels. For more information, see this blog post. | Boolean | False |
| classNeurons | To improve the user experience, a parameter that automatically multiplies the number of neurons provided with the number of classes used is added. If used, a hidden layer will have significantly more neurons allowing for higher performance when using one-hot encoding. | Boolean | True |
| inputs | Specifies the number of characters used as an input for the neural network. | Integer | 60 |
| neuronsPerLayer | Specifies the number neurons in each hidden layer. In most cases 2*inputs is sufficient. | Integer | 120 |
| layerCount | The total number of hidden layers used in the network. Generally four is the highest recommended value. | Integer | 4 |
| epochs | Number of real epochs where the entire dataset was passed through the neural network. | Integer | 1 |
| kerasEpochsPerEpoch | To receive frequent updates on large datasets, one can set this parameter so that keras calls the callbacks more often. Warning: This does interfere with the training optimizer, potentially causing negative results. | Integer | 256 |
| learningRate | The rate the neural network learns with. The most important hyperparameter to test and tweak. | Float | 0.005 |
| outputs | Number of outputs in characters. It is highly discouraged to use more than one output. | Integer | 1 |
| dropout | Dropout is a regularization technique to make sure the network learns instead of remembering trainings data. Values from 0.15 to 0.4 can be used without significantly harming the network. | Integer | 0.35 |
| batchSize | The batch size is the number of training samples the neural network uses to make one update to the weights. A higher number improves the speed and reduces overfitting but might also harm the network. | Integer | 1024 |
| valSplit | Specifies how much of the input dataset should be used for validation at the end of every keras epoch. Generally 100MB or more should be set aside for validation. | Float | 0.1 |
| verbose | Used to set a verbosity level in keras. According to keras' documentation: 0 = silent, 1 = progress bar, 2 = one line per epoch. |
Integer | 1 |
| outCharCount | Number of characters to be recursively generated using a test string at every end of a keras epoch. | Integer | 512 |
| changePerKerasEpoch | Sets the percentage of the original batch size that should be added to the current batch size after every keras epoch. Example: Epoch 1: Batch Size 100; Epoch 1: Batch Size 200; Epoch 3: Batch Size 300 |
Float | 0.25 |
| activation | Activation function used in the neural network. The default is gelu but other activation functions can be used as well. | String | 'gelu' |
| weightFolderName | Defines the name of the folder weights are saved to and loaded from. | String | 'MLP_Weights' |
| testString | A string that is used as an input for the neural network to predict at the end of every keras epoch. If set to None, it will default to this string. | String | None |
| charSet | A set of characters used in the text used as input. Leaving at None will make the network assume it is this char set. A text can be formatted to this format by passing prepareText=True to your charnet instance or explicitly calling charnet.prepareText(). |
String | None |
{kind=link}
{kind=link}
- Explain parameters
- Make code humanly readable
- Add config dict instead of enforcing parameters to be assigned
- Create Notebooks to link to
- Add link to example datasets
- Add proper example showing most interface functions using the trump dataset as an example.
- Add example output