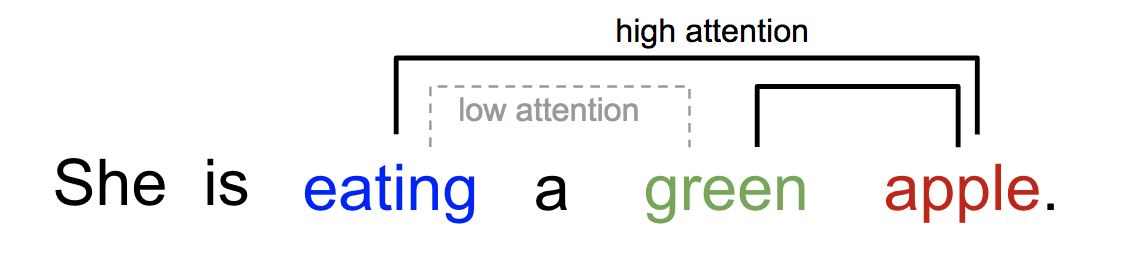
Imagine you're reading a long novel. You don't read every word with the same level of focus. Instead, you pay more attention to certain parts, like the plot twists or character developments. This is similar to how attention works in a language model.
The model presented in this repository is a type of language model that predicts the next word with a self-attention mechanism.
- Self-Attention: The self-attention mechanism allows the model to focus on different parts of the input sequence based on their relevance to the current output. This is achieved by assigning weights to each input element, with larger weights indicating greater importance.
How Does Self-Attention Work?
- Embedding: Each word in the input sequence is converted into a numerical representation called an embedding.
- Query, Key, and Value: For each word, three vectors are calculated: a query, a key, and a value.
- Attention Scores: The dot product between the query of one word and the keys of all other words is calculated. This gives a score representing the similarity between the words.
- Softmax: The scores are normalized using the softmax function to obtain attention weights.
- Context Vector: The weighted sum of the value vectors, using the attention weights, creates a context vector. This context vector captures the relevant information from the entire sequence.
The Code in Action
- Word Embeddings: The code initializes random word embeddings. In practice, pre-trained embeddings like Word2Vec or GloVe can be used for better performance.
- Context Window: The code defines a context window, specifying the number of words to consider before the current word.
- Self-Attention: The code calculates attention scores, applies softmax, and creates the context vector.
- Prediction: The context vector is used to predict the next word, often using a simple linear layer or a more complex model.
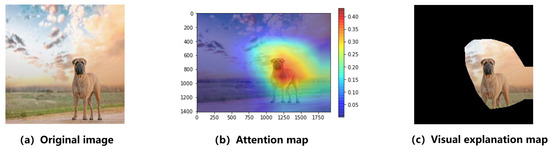
(Image Credit to article Attention Map-Guided Visual Explanations for Deep Neural Networks )
It all started with: "Attention is all you need."
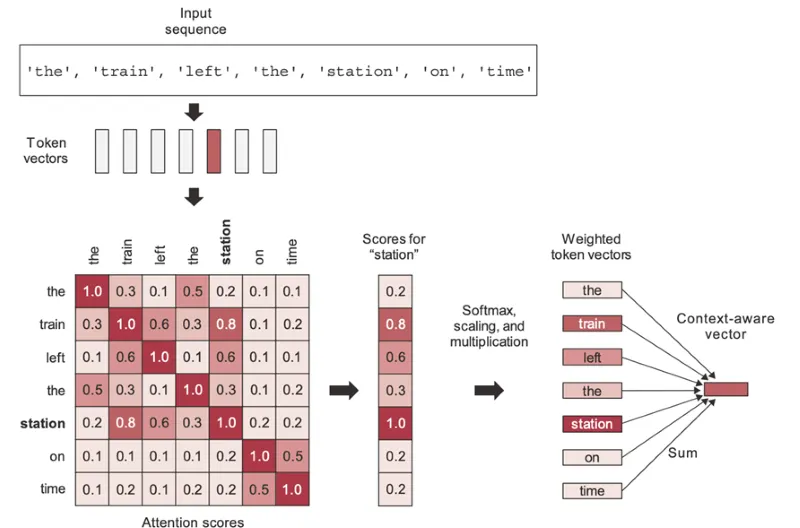
In the above image/example, there are 7 sequences in the sentence ‘the train left the station on time’, and we can see a 7x7 attention score matrix.
According to the self-attention scores depicted in the picture, the word ‘train’ pays more attention to the word ‘station’ rather than other words in consideration, such as ‘on’ or ‘the’. Alternatively, we can say the word ‘station’ pays more attention to the word ‘train’ rather than other words in consideration, such as ‘on’ or ‘the’.
Read more here: Self-Attention
Attention is a mechanism that allows a language model to focus on different parts of its input sequence based on their relevance to the current output. This is achieved by assigning weights to each input element, with larger weights indicating greater importance. These weights are calculated using a similarity metric, such as the dot product, between the query vector and each key vector in the input sequence.
For instance, in translation, attention helps the model concentrate on words or phrases that are semantically connected, leading to more accurate translations. On the other hand, this same mechanism can be exploited to generate misleading or biased text by directing the model's focus towards specific information.
Attention and Quality:
- Positive impact: Attention allows LLMs to focus on the most relevant parts of the input sequence when generating a response. This leads to responses that are more coherent, relevant, and grammatically correct.
- Negative impact:
- Focus on misleading information: If the input contains misleading or irrelevant keywords, the LLM's attention might be drawn to them, resulting in inaccurate, nonsensical or other undesired responses.
- Missing key information: The LLM might overlook crucial information if the wording is different from what it's trained on.
In this guide, we will explore the concept of attention through a Python code snippet that uses the self-attention mechanism to predict the next word in a sentence.
We will implement a basic language model that uses self-attention to predict the next word in a sentence.
The core functionality relies on the self-attention mechanism.
Imagine you're trying to teach a computer about the English language. You start by assigning each word a unique numerical identifier. This is similar to how we create word representations.
- Word: "cat"
- Representation: [0.2, 0.5, -0.3]
These numbers, or embeddings, are randomly initialized. Over time, as the model learns from data, these embeddings will adjust to better represent the meaning and context of the words.
Imagine you're reading a sentence: "The quick brown fox jumps over the lazy dog." To understand the meaning, you focus on certain words more than others. Self-attention mimics this human intuition.
- Query: "jumps" (the word we're trying to understand)
- Keys: "The," "quick," "brown," "fox," "over," "the," "lazy," "dog" (all the words in the sentence)
- Values: The embeddings of these words
The model calculates a similarity score between the query and each key. This score represents how relevant each word is to understanding "jumps." For instance, "fox" and "jumps" might have a high similarity score.
The similarity scores are converted into probabilities using the softmax function. This ensures that the probabilities sum to 1.
- Similarity Scores: [0.2, 0.5, 0.1, 0.6, 0.3, 0.2, 0.4, 0.1]
- Probabilities: [0.12, 0.28, 0.06, 0.32, 0.17, 0.12, 0.23, 0.06]
These probabilities indicate the importance of each word in the context of understanding "jumps."
The model then uses these probabilities to weigh the influence of each word's embedding. The word with the highest combined weight is predicted as the next word.
- Weighted Sum: [0.12 * "The" + 0.28 * "quick" + ...]
- Predicted Next Word: "over" (based on the weighted sum)
-
Self-Attention: This is the key concept used in the
calculate_self_attentionfunction. It allows the model to focus on relevant parts of the input sequence (the sentence) when predicting the next word. -
Word Embeddings: The model uses randomly generated embeddings to represent each word. These embeddings are then projected into query, key, and value vectors which are used for calculating the attention weights.
Overall, the model can be considered a simple language model with a self-attention mechanism for next word prediction. It demonstrates the core idea of self-attention but lacks the complexity of more advanced models like Transformers, which utilize this mechanism extensively.
import numpy as npWe start by importing the numpy library, which provides support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays.
The softmax function is a function that turns a vector of K real values into a vector of K real values that sum to 1. The input values can be positive, negative, zero, or greater than one, but the softmax transforms them into values between 0 and 1, so that they can be interpreted as probabilities. If one of the inputs is small or large, the softmax function squashes it, which helps in mitigating the exploding and vanishing gradient problems.
def softmax(x):
"""
This softmax function is often used in machine learning and deep learning to convert
a vector of real numbers into a probability distribution.
Each output value is between 0 and 1 (inclusive), and the sum of all output values is 1.
"""
# Subtract the max value in the input array from all elements for numerical stability.
# This ensures that all values in the array are between 0 and 1, which helps prevent potential overflow or underflow issues.
x -= np.max(x)
# Apply the exponential function to each element in the array.
# This transforms each value in the array into a positive value.
exp_x = np.exp(x)
# Divide each element in the array by the sum of all elements in the array.
# This normalizes the values so that they all add up to 1, which is a requirement for a probability distribution.
softmax_x = exp_x / np.sum(exp_x)
# Return the resulting array, which represents a probability distribution over the input array.
return softmax_xThe create_word_representations function takes a list of sentences as input and creates a dictionary mapping words to indices and vice versa. It also creates a list of word embeddings, which are randomly initialized.
def create_word_representations(sentences):
word_to_index = {}
index_to_word = {}
word_embeddings = []
for sentence in sentences:
for word in sentence.split():
if word not in word_to_index:
word_to_index[word] = len(word_to_index)
index_to_word[len(index_to_word)] = word
word_embeddings.append(np.random.rand(3)) # Random embeddings
return np.array(word_embeddings), word_to_index, index_to_wordRandomly generated embeddings serve as a starting point for the model to learn meaningful representations of words. They are essentially arbitrary numerical vectors assigned to each word.
- Initialization: Random embeddings provide a starting point for the model to learn meaningful representations of words. Without them, the model wouldn't know where to begin and its outputs would likely be nonsensical.
- Exploration: Randomness encourages the model to explore different directions in the solution space, potentially leading to better performance as it learns from the data.
Limitations of Random Embeddings:
- Arbitrary Starting Point: Random embeddings are essentially random guesses about how words should be represented. They may not capture any inherent relationships between words initially.
- Slower Learning: The model might take longer to converge on optimal word representations if the random starting points are far from the ideal ones.
Impact on Model Output:
The quality of the word embeddings directly affects the model's output:
- Better Embeddings, Better Outputs: If the model starts with good word representations that capture semantic relationships, it will be better at predicting the next word in a sentence and generating more coherent and relevant outputs.
- Poor Embeddings, Poor Outputs: With random embeddings, the model might struggle to understand the context and relationships between words. This can lead to nonsensical or grammatically incorrect outputs.
Example:
Consider the sentence "The quick brown fox jumps over the lazy dog."
- With good embeddings: The model might identify the relationship between "fox" and "jumps" and predict "jumps" as the next word.
- With poor embeddings: The model might struggle to connect "fox" to any meaningful word and might predict something unrelated, like "The" or "dog."
In summary, while randomly generated embeddings may seem arbitrary at first, they play a crucial role in initializing the model and allowing it to learn meaningful representations of words.
The calculate_self_attention function calculates the attention scores for each word in the context. It then computes the attention weights by applying the exponential function to the scores and normalizing them.
def calculate_self_attention(query, keys, values):
scores = np.dot(query, keys.T) / np.sqrt(keys.shape[1])
attention_weights = np.empty_like(scores)
for i in range(len(scores)):
if len(keys[i].shape) == 1: # Check if 1D array
attention_weights[i] = np.exp(scores[i]) # No need to sum for unique words
else:
attention_weights[i] = np.exp(scores[i]) / np.sum(np.exp(scores[i]), axis=1, keepdims=True)
return attention_weightsThe attention weights show how much importance the model assigns to each word in the context when predicting the next word. Higher weights indicate greater relevance.
- The: 2.1307
- quick: 2.5428
- brown: 1.9087
- fox: 2.6365
- jumps: 2.2119
- over: 1.2500
- the: 2.1166
- lazy: 2.5802
- dog: 1.5677
As you can see, the words "quick," "fox," and "lazy" have the highest weights, suggesting they are the most important for predicting the next word.
The predict_next_word_with_self_attention function uses the self-attention mechanism to predict the next word in a sentence. It first calculates the context embeddings by averaging the embeddings of the words in the context window. It then calculates the attention weights and applies the softmax function to get a probability distribution over the words. The next word is predicted by sampling from this distribution.
def predict_next_word_with_self_attention(current_word, context_window, words, word_embeddings, word_to_index, index_to_word):
context_embeddings = word_embeddings[[word_to_index[word] for word in context_window]]
query = np.mean(context_embeddings, axis=0) # Average context embeddings
keys = values = np.array([word_embeddings[word_to_index[word]] for word in words])
attention_weights = calculate_self_attention(query, keys, values)
attention_probabilities = softmax(attention_weights)
predicted_index = np.argmax(attention_probabilities) # Select the word with the highest probability
predicted_word = index_to_word[predicted_index]
return predicted_word, attention_probabilities
This code is implementing a simple version of the self-attention mechanism, which is a key component in Transformer models used in natural language processing. The self-attention mechanism allows the model to weigh the importance of words in a sentence when predicting the next word.
Here's a breakdown of the code:
-
create_word_representations(sentences): This function takes a list of sentences as input and creates a word-to-index and index-to-word dictionary, and a list of word embeddings. Each unique word in the sentences is assigned a unique index and a random 3-dimensional vector as its embedding. -
calculate_self_attention(query, key, value): This function calculates the self-attention weights and the output vector. The attention weights are calculated by taking the dot product of the query and key, scaling it, and applying the softmax function. The output vector is the weighted sum of the value vectors, where the weights are the attention weights. -
predict_next_word_with_self_attention(current_word, words, word_embeddings, word_to_index, index_to_word): This function predicts the next word given the current word and a list of words (context). It first retrieves the embeddings of the current word and the context words, then calculates the self-attention weights and output vector. The predicted next word is the word whose embedding is closest to the output vector.
Finally, we run the model on a set of sentences. For each sentence, the model predicts the next word given the current word "fox" and prints the attention weights for each word in the sentence and the predicted next word.
if __name__ == "__main__":
sentences = [
"The quick brown fox jumps over the lazy dog",
]
word_embeddings, word_to_index, index_to_word = create_word_representations(sentences)
current_word = "jumps"
context_window_size = 2 # Considering two words before the current word
for sentence in sentences:
words = sentence.split()
current_word_index = words.index(current_word)
context_window = words[max(0, current_word_index - context_window_size):current_word_index]
predicted_word, attention_probabilities = predict_next_word_with_self_attention(current_word, context_window, words, word_embeddings, word_to_index, index_to_word)
print(f"\nGiven the word: {current_word}")
print(f"Context: {' '.join(context_window)}") # Print context window
print(f"Sentence: {sentence}")
print("Attention Probabilities:")
for word, prob in zip(words, attention_probabilities):
print(f"\t{word}: {prob:.4f}")
print(f"Predicted next word: {predicted_word}\n")
print("""
The word embeddings are initialized randomly in this code.
This means that the relationships between different words are not captured in the embeddings,
which could lead to seemingly random attention probabilities.
""")
print(f"Prediction process: The model uses the context of the given word '{current_word}' to predict the next word. The attention mechanism assigns different weights to the words in the context based on their relevance. The word with the highest weight is considered as the most relevant word for the prediction.")
print(f"Attention Impact: The attention probabilities show the relevance of each word in the context for the prediction. The higher the probability, the more impact the word has on the prediction.\n")This code provides a basic model that uses self-attention to predict the next word in a sentence. It demonstrates the core idea of self-attention but lacks the complexity of more advanced models like Transformers, which utilize this mechanism extensively.
- The quality of the word embeddings used can significantly impact the model's performance.
- The size of the vocabulary and the complexity of the language can also affect the model's accuracy.
Intelligence is a Product of Training
The "intelligence" of an LLM is directly tied to the quality and diversity of its training data. Here's how:
- Data Bias: If the training data is biased, the LLM will also be biased in its outputs. For example, an LLM trained on mostly news articles might struggle to understand sarcasm or humor.
- Data Limitedness: The real world is vast and complex. LLMs can only process what they've been trained on. Limited data can lead to incomplete understanding and difficulty handling unexpected situations.
- Training Objectives: Ultimately, LLMs are optimized for the tasks they are trained on. An LLM trained for text summarization may not excel at creative writing tasks, even if the data is vast.
While we've discussed the basic concept of attention, it's important to note that there are several types of attention mechanisms used in different models. One of the most notable is multi-head attention, which is a key component of Transformer models.
NOTE: In most transformer models, the word embeddings remain constant throughout the training process. It's the model weights that are updated during training to improve the model's ability to represent and understand the data.
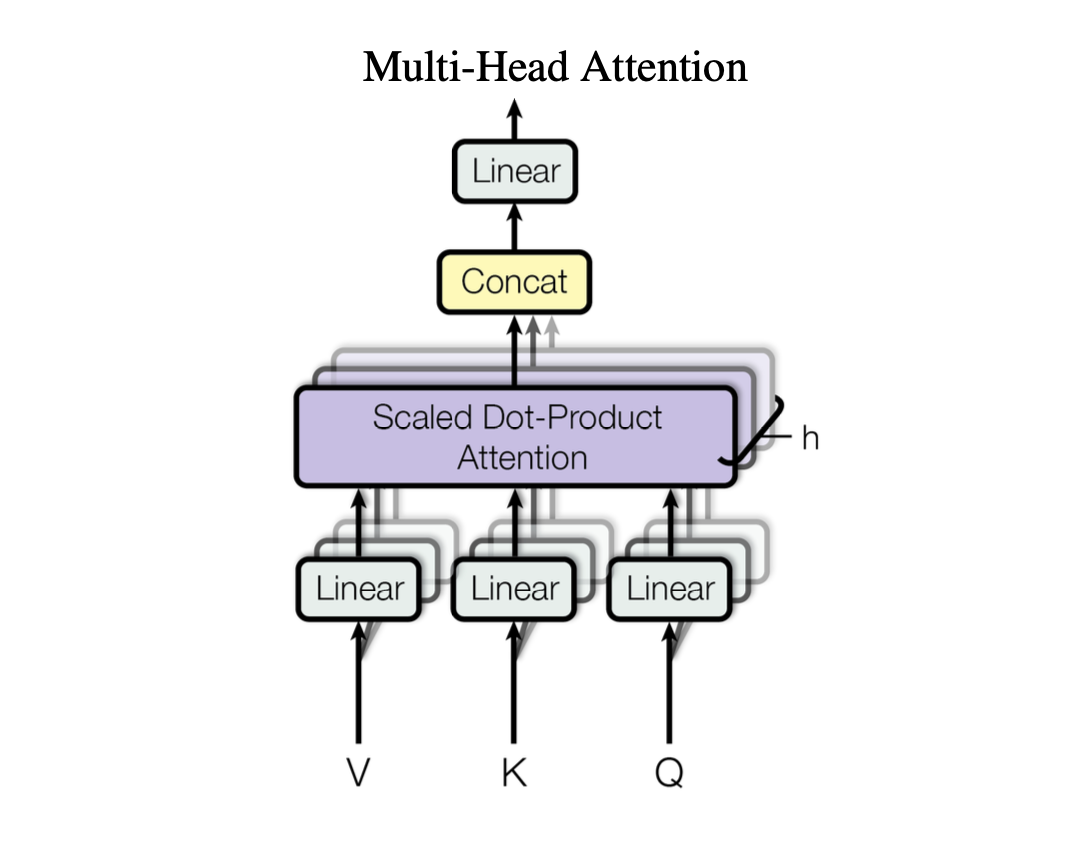
Multi-head attention is a type of attention mechanism that allows the model to focus on different parts of the input sequence simultaneously. It does this by splitting the input into multiple "heads" and applying the attention mechanism to each head independently. This allows the model to capture various aspects of the input sequence, such as different levels of abstraction or different types of relationships between words.
In the context of language models, multi-head attention can help the model understand complex sentences where different words have different relationships with each other. For example, in the sentence "The cat sat on the mat," the word "cat" is related to "sat" (the action the cat is performing) and "mat" (the location of the action). Multi-head attention allows the model to capture both of these relationships simultaneously.
The Challenges of LLM Intelligence
The "intelligence" of an LLM heavily depends on the quality and variety of its training data. Biases, limitations in the data itself, and narrow training objectives can all hinder a model's ability to represent the real world's complexities. Just like a student highlighting doesn't guarantee comprehension, attention in LLMs doesn't guarantee true understanding.
import numpy as np
def softmax(x):
"""
This softmax function is often used in machine learning and deep learning to convert
a vector of real numbers into a probability distribution.
Each output value is between 0 and 1 (inclusive), and the sum of all output values is 1.
"""
# Subtract the max value in the input array from all elements for numerical stability.
# This ensures that all values in the array are between 0 and 1, which helps prevent potential overflow or underflow issues.
x -= np.max(x)
# Apply the exponential function to each element in the array.
# This transforms each value in the array into a positive value.
exp_x = np.exp(x)
# Divide each element in the array by the sum of all elements in the array.
# This normalizes the values so that they all add up to 1, which is a requirement for a probability distribution.
softmax_x = exp_x / np.sum(exp_x)
# Return the resulting array, which represents a probability distribution over the input array.
return softmax_x
def create_word_representations(sentences):
word_to_index = {}
index_to_word = {}
word_embeddings = []
for sentence in sentences:
for word in sentence.split():
if word not in word_to_index:
word_to_index[word] = len(word_to_index)
index_to_word[len(index_to_word)] = word
word_embeddings.append(np.random.rand(3)) # Random embeddings
return np.array(word_embeddings), word_to_index, index_to_word
def calculate_self_attention(query, keys, values):
scores = np.dot(query, keys.T) / np.sqrt(keys.shape[1])
attention_weights = np.empty_like(scores)
for i in range(len(scores)):
if len(keys[i].shape) == 1: # Check if 1D array
attention_weights[i] = np.exp(scores[i]) # No need to sum for unique words
else:
attention_weights[i] = np.exp(scores[i]) / np.sum(np.exp(scores[i]), axis=1, keepdims=True)
return attention_weights
def predict_next_word_with_self_attention(current_word, context_window, words, word_embeddings, word_to_index, index_to_word):
context_embeddings = word_embeddings[[word_to_index[word] for word in context_window]]
query = np.mean(context_embeddings, axis=0) # Average context embeddings
keys = values = np.array([word_embeddings[word_to_index[word]] for word in words])
attention_weights = calculate_self_attention(query, keys, values)
attention_probabilities = softmax(attention_weights)
predicted_index = np.argmax(attention_probabilities) # Select the word with the highest probability
predicted_word = index_to_word[predicted_index]
return predicted_word, attention_probabilities
if __name__ == "__main__":
sentences = [
"The quick brown fox jumps over the lazy dog",
]
word_embeddings, word_to_index, index_to_word = create_word_representations(sentences)
current_word = "jumps"
context_window_size = 2 # Considering two words before the current word
for sentence in sentences:
words = sentence.split()
current_word_index = words.index(current_word)
context_window = words[max(0, current_word_index - context_window_size):current_word_index]
predicted_word, attention_probabilities = predict_next_word_with_self_attention(current_word, context_window, words, word_embeddings, word_to_index, index_to_word)
print(f"\nGiven the word: {current_word}")
print(f"Context: {' '.join(context_window)}") # Print context window
print(f"Sentence: {sentence}")
print("Attention Probabilities:")
for word, prob in zip(words, attention_probabilities):
print(f"\t{word}: {prob:.4f}")
print(f"Predicted next word: {predicted_word}\n")
print("""
The word embeddings are initialized randomly in this code.
This means that the relationships between different words are not captured in the embeddings,
which could lead to seemingly random attention probabilities.
""")
print("""
The input triggers the attention mechanism which is used to weight
the importance of different words in the sentence for the prediction of the next word.
""")
print(f"Prediction process: The model uses the context of the given word '{current_word}' to predict the next word. The attention mechanism assigns different weights to the words in the context based on their relevance. The word with the highest weight is considered as the most relevant word for the prediction.")
print(f"Attention Impact: The attention probabilities show the relevance of each word in the context for the prediction. The higher the probability, the more impact the word has on the prediction.\n")