课程实践-LLM技术挑战
本次实验使用了开源的 Intel Extension for Transformers(IEXT)或其组件(Neural Chat),在魔搭社区云环境开发基于大语言模型的新型应用。 Intel Extension for Transformers 主要分为硬件加速和软件加速两大加速技术: 硬件加速技术:
- 高级矢量扩展(AVX-512)。AVX-512是英特尔处理器中的一组指令集,旨在加速向量运算,特别适合于深度学习中的矩阵计算。IEXT利用AVX-512优化矩阵乘法、卷积操作等关键计算任务,从而显著提升变压器模型的训练和推理速度。
- Intel Deep Learning Boost (DL Boost)。DL Boost包含了一组加速深度学习推理的指令,特别是对低精度计算(如INT8)的支持。通过DL Boost,IEXT能够加速模型推理过程,尤其是在实时应用场景中表现出色。
- Intel GPU加速。Intel的GPU架构专门设计用于高效执行深度学习任务。IEXT支持英特尔GPU,利用其并行计算能力,进一步加速变压器模型的训练和推理。
软件加速技术:
- Intel OneDNN。OneDNN是一个高性能的深度学习加速库,包含一系列优化的数学内核。IEXT集成了OneDNN,优化变压器模型的基本运算(如卷积、归一化和矩阵乘法),显著提高整体计算效率。
- 图层优化(Graph Optimizations)。通过分析和优化计算图,减少冗余计算和内存访问。IEXT在执行计算图时进行图层优化和算子融合,减少计算开销和内存带宽消耗,提升模型执行效率。
- 量化技术(Quantization)。量化技术通过降低计算精度来减少计算量和内存占用,同时尽量保持模型精度。IEXT支持静态和动态量化,将模型参数从FP32转换为INT8,显著提升推理速度和节省内存。 IEXT是一个开源项目,提供详细的文档和示例代码。开发者可以访问和修改源码,根据具体需求进行定制,同时利用丰富的文档和示例快速上手。英特尔提供持续的技术支持和更新,确保IEXT能够利用最新的硬件和软件优化技术。因而IEXT是一个十分好用且实用的工具。
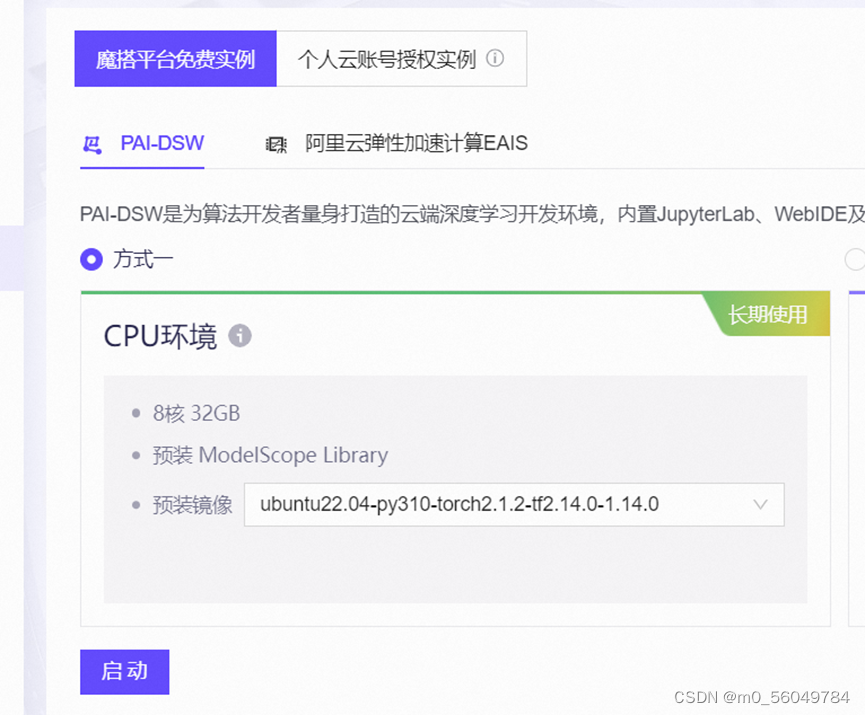
进入魔塔社区,启动CPU服务器:
cd /opt/conda/envs
mkdir itrex
wget https://idz-ai.oss-cn-hangzhou.aliyuncs.com/LLM/itrex.tar.gz
tar -zxvf itrex.tar.gz -C itrex/
//激活环境,安装对应的 kernel:
conda activate itrex
python -m ipykernel install --name itrex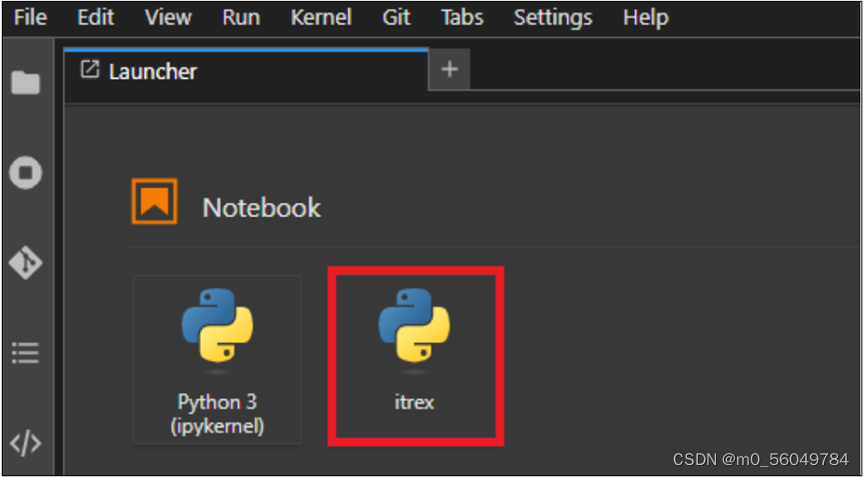
代码如下:
//基于 itrex kernel 新建 notebook,新建 cell,下载中文大模型:
! git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
//新建 cell,下载 embedding 模型:
! git clone https://www.modelscope.cn/AI-ModelScope/bge-base-zhv1.5.git
//准备知识库文件 sample.jsonl,在文件里面输入如下内容,保存文件。
{"content": "cnvrg.io 网站由 Yochay Ettun 和 Leah Forkosh Kolben 创
建.", "link": 0}代码如下:
//回到 notebook,新建 cell,添加以下代码构建 chatbot,点击运行:
from intel_extension_for_transformers.neural_chat import
PipelineConfig
from intel_extension_for_transformers.neural_chat import
build_chatbot
from intel_extension_for_transformers.neural_chat import plugins
from intel_extension_for_transformers.transformers import RtnConfig
plugins.retrieval.enable=True
plugins.retrieval.args['embedding_model'] = "./bge-base-zh-v1.5"
plugins.retrieval.args["input_path"]="./sample.jsonl"
config = PipelineConfig(model_name_or_path='./chatglm3-6b',
plugins=plugins,
optimization_config=RtnConfig(compute_dtype="int8",
weight_dtype="int4_fullrange"))
chatbot = build_chatbot(config)
//新建 cell,添加以下代码 disable retrieval,点击运行:
plugins.retrieval.enable=False # disable retrieval
response = chatbot.predict(query="cnvrg.io 网站是由谁创建的?")
print(response)
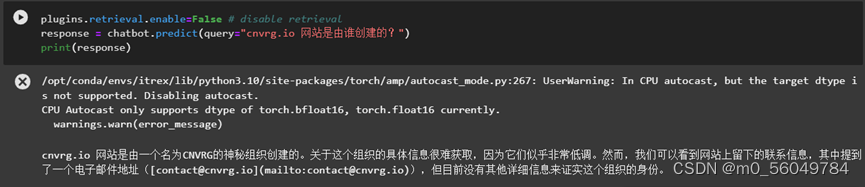
结果如下图,说明未开启IEXT的plugins时,chatbot回复的答案不是很准确。
//新建 cell,添加以下代码 enable retrieval,点击运行:
plugins.retrieval.enable=True # enable retrieval
response = chatbot.predict(query="cnvrg.io 网站是由谁创建的?")
print(response)
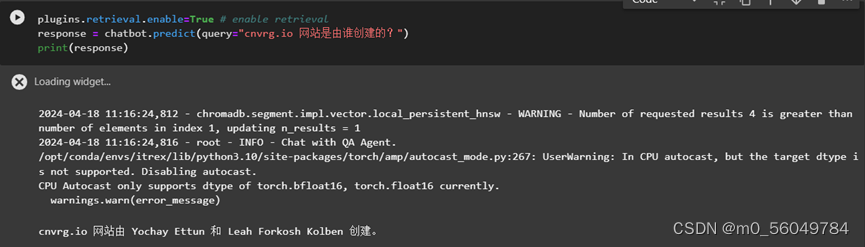
其结果如下图,说明开启IEXT的plugins后,chatbot回复的答案更加准确。
以上图片均来源于本人CSDN博客。附链接https://blog.csdn.net/m0_56049784/article/details/139122411?spm=1001.2014.3001.5502
Intel Extension for Transformers的手册、文档十分充足,用起来十分方便,而且优化的效果从实验来说,非常的明显,是一个非常好的开源工具。